


Issue #72 - Retrieval methods II

💊 Pill of the week
In the previous part, we explored similarity search and Maximum Marginal Relevance (MMR) in retrieval systems. These methods prioritized finding relevant documents based on content similarity.

In this section, we delve deeper into advanced retrieval techniques, such as self-query retrieval and contextual compression, which further enhance precision and relevance by leveraging metadata-based filtering and content refinement.
Self-Query Retrieval
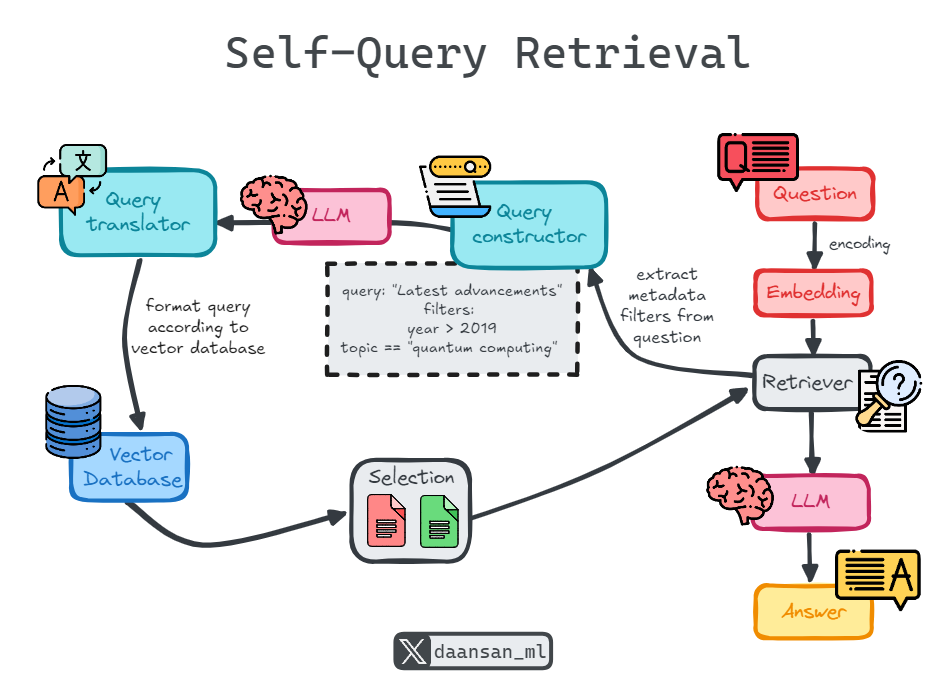
Self-query retrieval refers to a system's ability to query itself using a query-constructing language model chain (LLM). This process involves transforming a natural language query into a structured query. The structured query can then be used to search within a VectorStore, leveraging both semantic similarity and metadata-based filtering.
Unlike traditional retrieval methods that rely solely on semantic similarity, self-query retrieval allows the system to extract filters from the user’s natural language query. These filters can be applied to the metadata of stored documents, ensuring that the returned documents are not only semantically similar but also meet specific criteria embedded in the query.
This approach dramatically improves precision, especially in cases where metadata (e.g., document date, author, or category) is vital for filtering relevant results. This dual approach—combining semantic similarity and metadata filters—makes self-query retrieval an advanced and flexible method for improving relevance and precision in search results.
Advantages:
Combines semantic similarity with metadata-based filtering.
Retrieves more precise, contextually relevant results.
Reduces irrelevant document retrieval by applying metadata filters.
Applications:
Legal document retrieval where both content relevance and metadata (e.g., case law date) are critical.
Research databases where queries need to be refined by metadata, such as publication year or subject matter.
Enterprise search systems where filtering by document type, author, or access level is necessary.
Example: Suppose you query a system with "Latest advancements on quantum computing from MIT published in the last 5 years". The self-query retriever extracts metadata filters from the query (e.g., "published after 2019") and applies these to the VectorStore alongside the semantic similarity search.
from langchain.chains.query_constructor.base import AttributeInfo
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain_openai import ChatOpenAI
# Define metadata fields for research papers
metadata_field_info = [
AttributeInfo(
name="author",
description="The primary author of the research paper",
type="string",
),
AttributeInfo(
name="year",
description="The year the research paper was published",
type="integer",
),
AttributeInfo(
name="domain",
description="The domain of research such as ['physics', 'biology', 'computer science', 'chemistry']",
type="string",
),
AttributeInfo(
name="institution",
description="The academic or research institution where the work was conducted",
type="string",
),
]
document_content_description = "Summary of the research paper"
llm = ChatOpenAI(temperature=0)
# Create self-querying retriever
retriever = SelfQueryRetriever.from_llm(
llm,
vectorstore,
document_content_description,
metadata_field_info,
)
# Example query
docs = retriever.invoke("Latest advancements on quantum computing from MIT published in the last 5 years")In this process:
The system takes the user’s natural language query, such as “Find papers on quantum computing from MIT published in the last 5 years,” and uses an LLM chain to interpret the query and generate a structured query.
The structured query is applied to the metadata fields of the research papers in the VectorStore, extracting filters like "research domain: quantum computing," "institution: MIT," and "published after 2019."
The system then combines the semantic similarity results (retrieved based on the content of the papers) with the metadata-filtered documents to ensure that the final set of papers retrieved is not only related to quantum computing but also published by MIT within the last 5 years.
This ensures more accurate and targeted retrieval by combining the content-based similarity search with the constraints provided by the metadata fields in the structured query. This dual approach significantly improves the precision and context of the returned documents.
Contextual Compression
One of the key challenges in document retrieval is that you typically do not know which specific queries your system will face in advance. This means relevant information can often be buried within larger documents containing irrelevant or extraneous text. When passing these full documents through to an application, this can lead to unnecessary costs for large language model (LLM) calls, as well as poor response quality due to irrelevant content.
Contextual compression addresses this issue. Rather than returning retrieved documents as-is, it processes them in the context of the query, extracting and delivering only the most relevant information. This not only minimizes irrelevant text but also reduces computational cost by shortening the documents before presenting them.
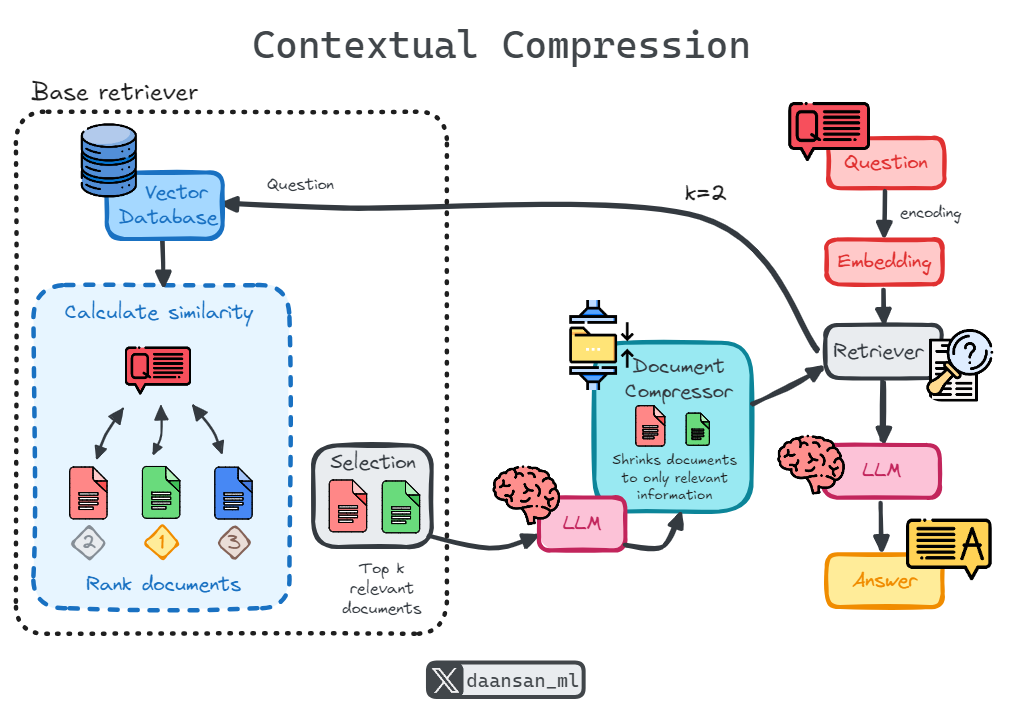
To implement contextual compression, you need two components:
Keep reading with a 7-day free trial
Subscribe to Machine Learning Pills to keep reading this post and get 7 days of free access to the full post archives.