



💊 Pill of the week
Feature importance is the quantification of the predictive power of individual input variables or features in a model. It provides insights into which features contribute most significantly to the model's performance in making accurate predictions or classifications. Understanding feature importance aids feature selection, model interpretation, and identifying critical factors driving the outcomes.
We introduced this concept a month ago:

But today we are going to put it into practice!
The data
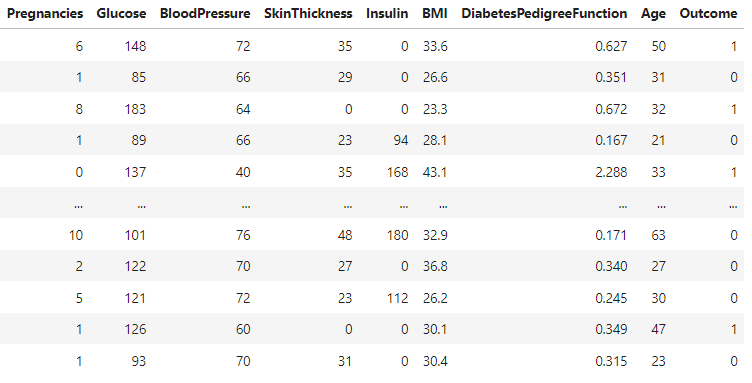
We will analyse the most important factors (diagnostic measurements) that allow for an accurate prediction of whether a patient has diabetes. We will use a dataset from the National Institute of Diabetes and Digestive and Kidney
Diseases. We can find several variables, the independent variables
(several medical predictor variables) and the target or dependent variable (whether the person has diabetes or not).
Importance
But before starting, why is Feature Importance important? It is crucial for several reasons:
Model Interpretability: Understanding which features are most important in making predictions helps to interpret the model's behavior.
Feature Selection: Feature importance helps in identifying the most relevant features for making predictions. In many cases, datasets contain a large number of features, some of which may be irrelevant or redundant.
Dimensionality Reduction: By identifying and focusing on the most important features, feature importance analysis aids in reducing the dimensionality of the dataset. This simplifies the model, making it more computationally efficient and less prone to overfitting.
Insights for Feature Engineering: Feature importance analysis provides insights into which features contribute most significantly to the target variable. This information can guide feature engineering efforts by highlighting areas where additional domain knowledge or feature transformations might be beneficial.
Model Debugging and Diagnosis: Understanding feature importance can help diagnose issues with the model. For instance, if a highly important feature is not available or has incorrect values, it could signal data quality issues or feature engineering mistakes.
Communication: Feature importance analysis facilitates communication between data scientists and domain experts. It provides a common ground for discussing which features are driving the predictions and helps in explaining model behavior to stakeholders who may not have a deep understanding of machine learning algorithms.
Random Forest model
We will start by training a Random Forest classifier model. If you remember, decision-tree-based models allow for the estimation of the feature importance based on the assessment of the contribution of each feature to reducing impurity or error during the decision-making process.
This first approach yielded the following results:
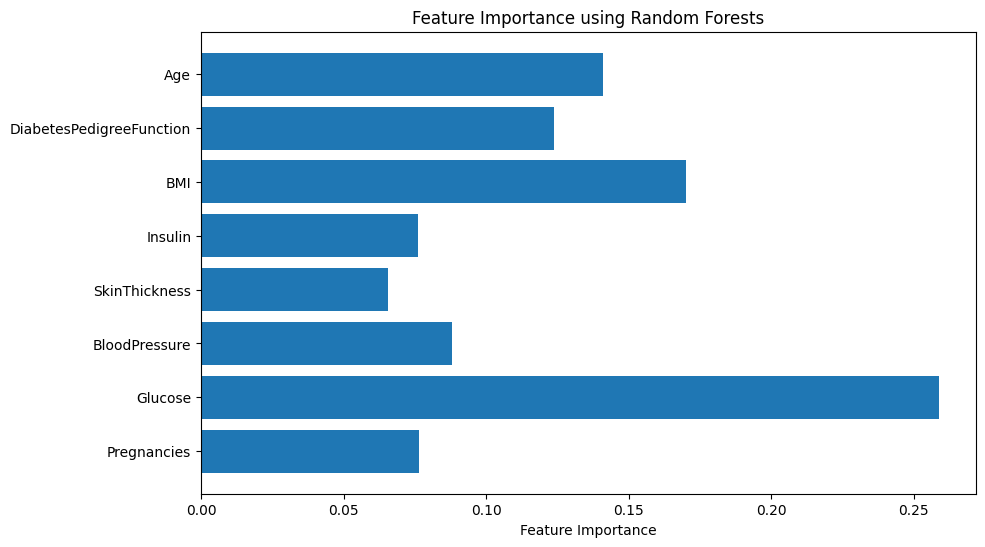
It seems that glucose is the main factor, followed by BMI, age and diabetes pedigree function.
Getting this straight from the model is not always possible. That is why there exist techniques that address this issue.
Correlation matrix
One basic approach would be to compute the correlation matrix and see how each feature correlates with the outcome feature:
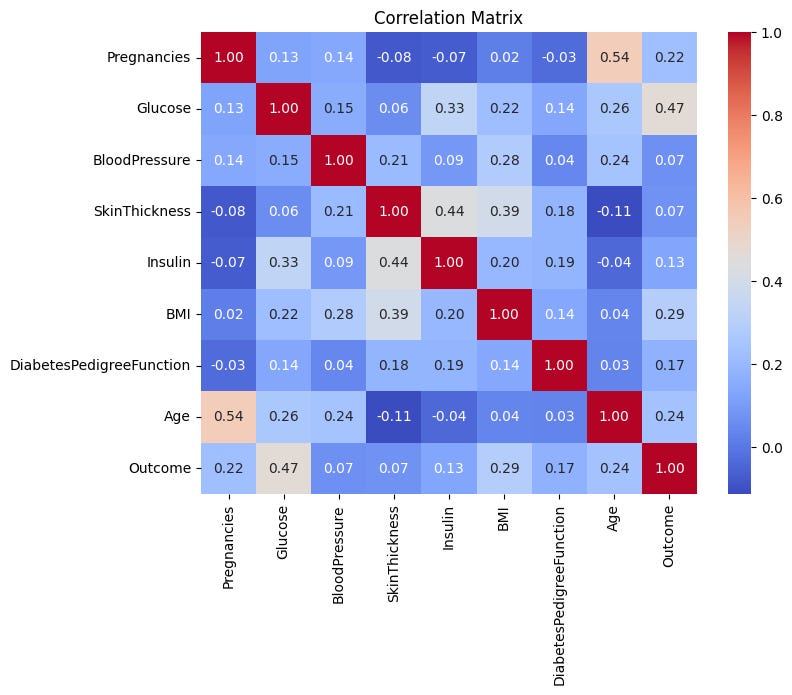
Let’s simplify this information in a bar chart:
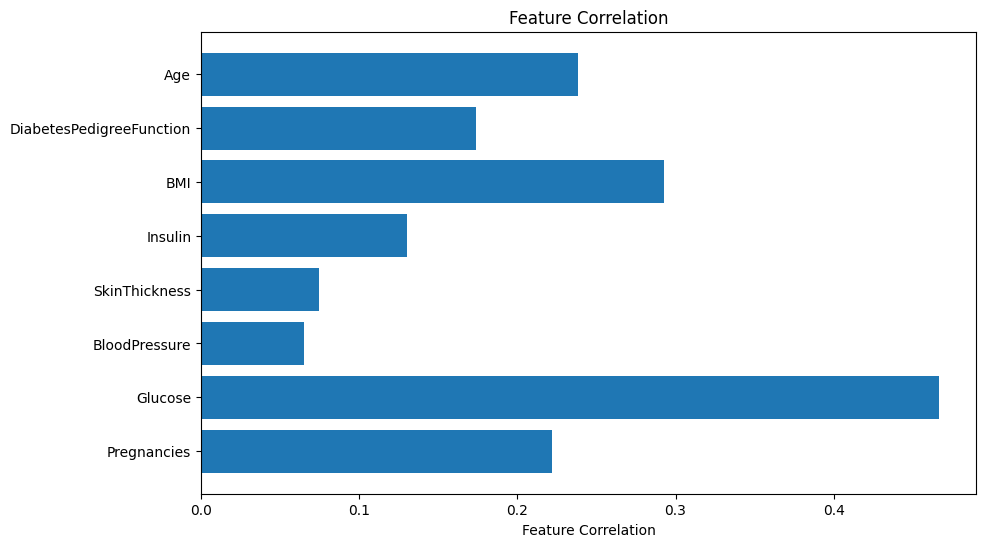
Again we see that glucose is the main predictor, whereas in this case it’s followed by the BMI, age and pregnancies.
The correlation matrix approach is not the best for assessing feature importance because it assumes linear relationships, ignores non-linear connections, struggles with multicollinearity, and cannot capture complex interactions or the combined effects of multiple features on the target variable. Instead, other more advanced techniques are preferred for their ability to handle these complexities and provide more accurate assessments of feature importance.
Permutation importance
Permutation importance is another model-agnostic method that computes feature importance for any model by shuffling the values of each feature one at a time and measuring the resulting change in model performance. The process works by breaking the relationship between each feature and the target variable, then observing the impact on the model’s performance. A higher decrease in performance upon shuffling indicates greater feature importance.
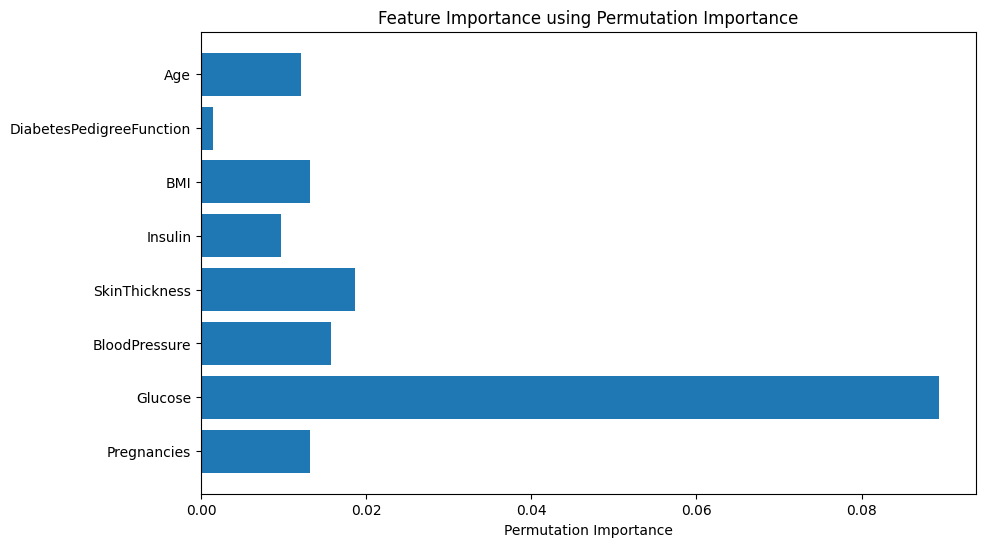
It matches the previous results, but it seems that glucose is way more important than the other predictors.
This technique is better because it captures non-linear relationships and interactions, handles multicollinearity, reflects true predictive power, can be applied to complex models, and is resilient to outliers.
However, it lacks the individualized interpretations, capturing of interactions, and directionality of feature effects that SHAP provides.
SHAP
SHAP (SHapley Additive exPlanations) values offer a unified measure of feature importance that allocates the contribution of each feature to the prediction for every possible combination of features. This method ensures a fair distribution of contributions, as it respects both efficiency and symmetry among features.
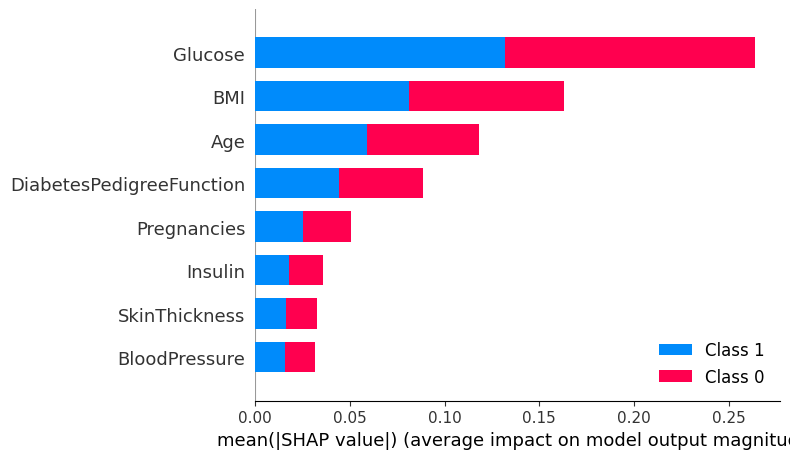
Again, glucose is the clear winner, followed by BMI, age and diabetes pedigree function.
However, this method can be computationally expensive and other simpler methods can be just fine depending on your problem.
Recursive Feature Elimination
This is not a feature importance technique, but I think it is interesting for you to also know it. It is an iterative method used for feature selection. The goal of feature selection is to identify and remove unnecessary features from the data that do not contribute, or may even decrease, the predictive performance of the model. RFE achieves this by recursively fitting the model, ranking the features based on their impact on model performance, and removing the least important feature at each step. This process continues until all features have been evaluated and ranked.
However, it’s worth noting that it can also be computationally expensive for models with a large number of features, as it involves repeatedly fitting the model and evaluating its performance. Also, it doesn’t calculate importance, it only ranks features by importance order.
1: Glucose
2: BMI
3: Age
4: DiabetesPedigreeFunction
5: BloodPressure
6: Insulin
7: Pregnancies
8: SkinThicknessAgain, glucose is the clear winner, followed by BMI and age.
The code
You can find a notebook with all the code at the end of this newsletter issue!
🎓Learn Advanced Machine Learning Concepts!*

Do you want to learn more about Model Interpretability and Feature Selection? Ready for a deeper dive?
Explore feature engineering and feature selection methods
Explain interpretable and black box models with LIME, Shap, partial dependency plots and more.
Enroll today and take the next step in mastering the world of data science!
*Sponsored: by purchasing any of their courses you would also be supporting MLPills.
🤖 Tech Round-Up
This week's TechRoundUp comes full of AI news. From Google’s brand new model Gemma to AI giants pact, the future is zooming towards us! 🚀
Let's dive into the latest Tech highlights you probably shouldn’t this week 💥
It is the next-gen open AI models for responsible development.
Offering tools & models for safer AI applications, it's set to revolutionize AI use responsibly.
Samsung is planning to expand AI features to more devices, enhancing user experiences with One UL 6.1 update.
Get ready for smarter, more intuitive device interactions.
3️⃣ Google DeepMind commits to AI safety
It is founding a new organization, focusing on ethical AI development.
A bold step towards responsible AI innovation.
4️⃣ Amazon unveils its largest text-to-speech model
Pushing the boundaries of natural sounding digital voices.
A leap forward in making technology more accessible.
With AI scrutiny, aiming to maintain fair competition and innovation in the AI landscape.
A critical move for the future of AI regulation.
🛠️ Do It Yourself!
You can practise all these concepts thanks to this notebook. You will need to do some research but don’t worry, next week I’ll unveil the answers!
Practise here:
Keep reading with a 7-day free trial
Subscribe to Machine Learning Pills to keep reading this post and get 7 days of free access to the full post archives.