



DIY#13 - Sentiment Analysis with Bag-of-Words


💊 Pill of the Week
Today we’re diving into sentiment analysis—a cool way to teach our models to decide if a movie review is cheering us on or giving us the boot. We’ll first introduce the NLP technique “Bag-of-Words” and then we’ll use an IMDb movie reviews dataset, clean the text, tokenize it, create a bag-of-words representation, and finally train a logistic regression model. Let’s get our hands dirty and see exactly what’s going on!
Thanks to for all the code and explanations!
Bag-of-Words
Before we jump into the coding fun, let's explore the Bag-of-Words (BoW) method, which serves as a fundamental building block in natural language processing and text analysis.
What It Is
Bag-of-Words is a simple yet powerful technique that converts text documents into numerical vectors that machine learning algorithms can understand. The name "bag" comes from the fact that this method disregards grammar and word order, treating text as an unordered collection (or bag) of words.
The method works by:
Splitting each text (or review) into individual words (tokens).
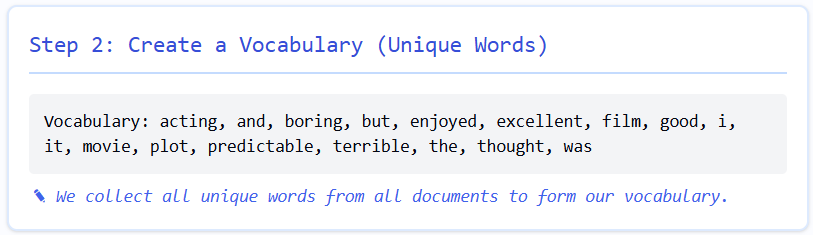
Building a vocabulary of all unique words found across all documents in the corpus.
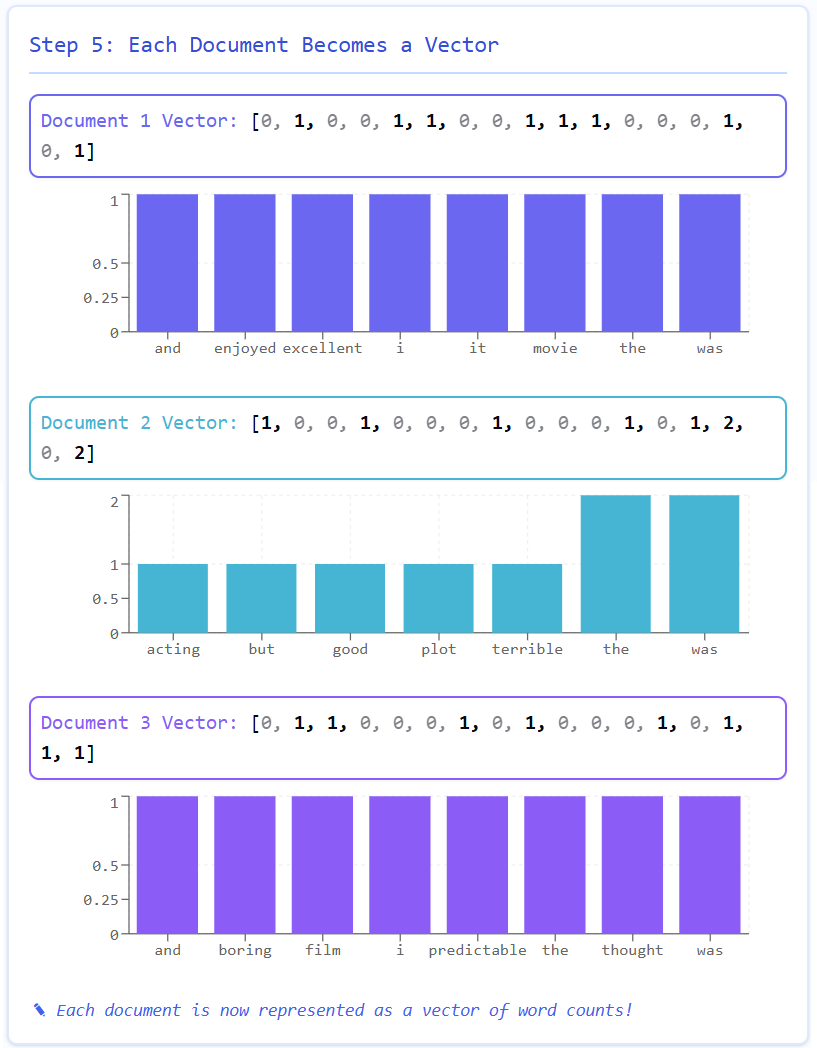
Representing each document as a numerical vector where each element corresponds to the count of a specific word from the vocabulary.
The Historical Context
The Bag-of-Words approach has roots in information retrieval systems from the 1950s and gained popularity in the 1990s with the growth of digital document collections. Despite its simplicity compared to modern deep learning approaches, BoW remains relevant because it's computationally efficient and surprisingly effective for many text classification tasks, including sentiment analysis.
Why It Works
Since natural language contains thousands or even millions of unique words, but each individual document (like a movie review) only uses a small subset of those words, most positions in these vectors are zero. This "sparsity" makes it computationally efficient to store and process, even for large datasets.
Additionally, certain words strongly correlate with sentiment. For example, words like "excellent" and "terrible" are powerful indicators of positive and negative sentiment, respectively.
The BoW model captures these correlations effectively, making it well-suited for sentiment analysis tasks.
A Concrete Example
Let's bring this to life with a more detailed example to really understand how BoW works:
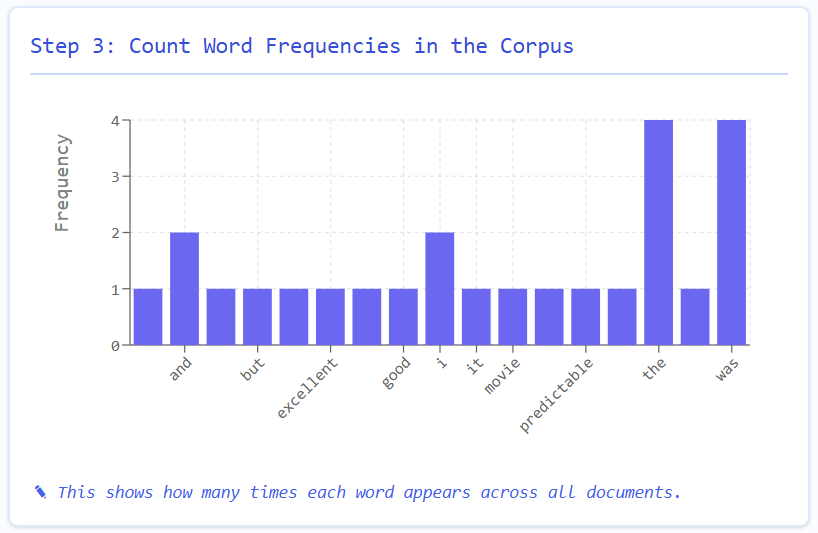
Imagine we have three movie reviews in our corpus:
"The movie was excellent and I enjoyed it."
"The acting was terrible but the plot was good."
"I thought the film was boring and predictable."
The BoW approach transforms these text documents into numerical vectors through a systematic process:


📌 Key Insights:
BoW ignores word order and just counts occurrences
Documents with similar sentiment often share key words
Notice how sentiment words like "excellent", "terrible", and "boring" stand out in their respective documents
Perfect for sentiment analysis as positive/negative words get their own dimensions
Each review becomes a point in a multi-dimensional space where ML algorithms can find patterns
Limitations and Considerations
While powerful, BoW has some limitations to keep in mind:
It ignores word order, which can sometimes be important ("not good" has a different meaning than "good not").
It creates high-dimensional, sparse vectors when vocabulary is large.
Common words like "the" or "and" may dominate counts without contributing much meaning.
We'll address some of these limitations in our preprocessing steps, and many advanced NLP techniques build upon this foundation by addressing these weaknesses.
Now that we understand the conceptual framework, let's dive into implementing Bag-of-Words for our sentiment analysis task!
🎓Further Learning*
Let us present: “From Beginner to Advanced LLM Developer”. This comprehensive course takes you from foundational skills to mastering scalable LLM products through hands-on projects, fine-tuning, RAG, and agent development. Whether you're building a standout portfolio, launching a startup idea, or enhancing enterprise solutions, this program equips you to lead the LLM revolution and thrive in a fast-growing, in-demand field.

Who Is This Course For?
This certification is for software developers, machine learning engineers, data scientists or computer science and AI students to rapidly convert to an LLM Developer role and start building
*Sponsored: by purchasing any of their courses you would also be supporting MLPills.
🛠️ Do It Yourself
Since last week we missed the issue, this one we will compensate with a longer one: theory + practice! Apologies for that and I hope you like it!
At the end, as usual, you’ll get a notebook with all the code!!
These are the steps:
Load and Prepare Data: Import necessary tools and load the movie review data, setting the stage for analysis.
Clean the Text: Remove unwanted elements like HTML and punctuation, making the text ready for analysis by standardizing it.
Convert Text to Numbers: Transform the cleaned text into numerical data using a "bag-of-words" model, so the computer can understand it.
Train a Predictive Model: Split the data into training and testing sets, and train a logistic regression model to predict sentiment.
Analyze the Results: Interpret the model's performance and understand which words contribute to positive or negative reviews.
Let’s finally begin!
Step 1: Importing Libraries & Loading the Data
First things first: we import necessary libraries and load the data from GitHub.
We’re using pandas to load a CSV file directly from a GitHub repository that contains thousands of IMDb reviews. This dataset has two columns: one for the review text and one for the sentiment (labeled "positive" or "negative").
import numpy as np
import pandas as pd
# Set a fixed seed to ensure our results are reproducible.
np.random.seed(42)
# Load the IMDb movie reviews dataset from GitHub.
# Note: This dataset contains text reviews and sentiment labels.
url = (
"https://raw.githubusercontent.com/Ankit152/IMDB-sentiment-analysis/refs/heads/master/IMDB-Dataset.csv"
)
df = pd.read_csv(url)
# Check the shape of the data (rows, columns) and preview the first few records.
print("Data shape:", df.shape)
print(df.head())
What’s happening?
We set the seed for reproducibility.
We load the CSV from GitHub.
We print out the shape and a preview so we know the data is what we expect.
Step 2: Preprocessing the Text
Before we train a model, our text needs some cleaning. This step removes unwanted HTML tags, punctuation, and normalizes everything to lowercase. We also extract emoticons because they can be full of sentiment (think of :-) versus :().
import re
def preprocessor(text):
"""
Clean the input text:
- Remove HTML markup.
- Extract emoticons and preserve them.
- Remove non-word characters (like punctuation) and convert to lowercase.
- Append cleaned emoticons (without the hyphen) back to the text.
"""
# Remove HTML tags using regex
text = re.sub(r"<[^>]*>", "", text)
# Find emoticons (patterns like :), :-), :D, etc.)
emoticons = re.findall(r"(?::|;|=)(?:-)?(?:\)|\(|D|P)", text)
# Remove non-word characters, change text to lowercase, and append emoticons at the end.
text = re.sub(r"[\W]+", " ", text.lower()) + " " + " ".join(emoticons).replace("-", "")
return text
# Apply the preprocessor to our reviews
df["review_clean"] = df["review"].apply(preprocessor)
# Print a sample cleaned review (displaying the last 100 characters for brevity)
print("\nSample cleaned review:", df.loc[0, "review_clean"][-100:])
More details:
Removing HTML Tags (
<[^>]*>)
• Looks for the<character and captures everything until the next>, removing HTML elements such as<div>or<br>.Extracting Emoticons
• The pattern(?::|;|=)(?:-)?(?:\)|\(|D|P)finds common emoticons (like:-),:D), ensuring emotional cues are not lost.Cleaning Text with
[\W]+
• Replaces sequences of non-word characters (anything besides letters, digits, or underscores) with a space, standardizing the text while keeping the emoticons to preserve sentiment.
Step 3: Tokenizing & Building the Bag-of-Words Model
Tokenization is simply breaking text into individual words (tokens). The bag-of-words approach will create a vocabulary of unique words and count the number of times each appears in a review. Here, we use scikit-learn’s CountVectorizer to do the heavy lifting.
from sklearn.feature_extraction.text import CountVectorizer
# Instantiate the CountVectorizer.
# This will first split our text into tokens and then count occurrences.
vectorizer = CountVectorizer()
# Fit the vectorizer on our cleaned review texts and transform them into numerical feature vectors.
X = vectorizer.fit_transform(df["review_clean"])
# Let’s inspect a small portion of the resulting vocabulary.
print("\nSample vocabulary mapping (word -> index):")
sample_vocab = dict(list(vectorizer.vocabulary_.items())[:10])
print(sample_vocab)
# Also print the bag-of-words array for the first 3 reviews.
print("\nBag-of-words representation for the first 3 reviews:")
print(X[:3].toarray())
Explanation:
Tokenization & Vocabulary Building:
•CountVectorizersplits each review into words (tokens) and collects unique words into a large vocabulary.Vector Representation:
• Each review is then transformed into a vector where each number shows how many times a word from the vocabulary appears.Sparse Matrix:
• Since most reviews only use a small fraction of the full vocabulary, many entries are zero, resulting in a sparse matrix.Example:


Step 4: Splitting Data & Training a Logistic Regression Model
Next, we transform the sentiment labels into a binary format (e.g., positive = 1, negative = 0), split our data into training and test sets, and then train a logistic regression classifier. Logistic regression is a popular choice due to its simplicity and interpretability—its coefficients tell us which words influence predictions.
Keep reading with a 7-day free trial
Subscribe to Machine Learning Pills to keep reading this post and get 7 days of free access to the full post archives.