

Issue #101 – SMOTE’s Limitations in Modern ML


💊 Pill of the Week
In imbalanced classification problems—like fraud detection, cancer diagnosis, or spam filtering—getting the model to recognize rare cases is crucial. For years, a go-to solution was SMOTE (Synthetic Minority Over-sampling Technique), which generates synthetic examples for the minority class by interpolating between nearby points.
Sounds smart, right?
But today, many machine learning engineers treat SMOTE as a relic: occasionally useful, but often harmful or outdated. In this issue, we’ll walk through what SMOTE is, where it fails, what better modern strategies exist, and the rare cases where SMOTE might still work.
What Is SMOTE?
SMOTE was introduced in 2002 to solve the class imbalance problem.
Rather than:
Undersampling the majority class (which throws away data), or
Naively duplicating minority class samples (which causes overfitting),
SMOTE generates new synthetic samples by interpolating between real minority examples.
How it works:
Pick a minority instance at random.
Find its k nearest minority neighbors.
Generate a synthetic point along the line between the original and one of its neighbors.
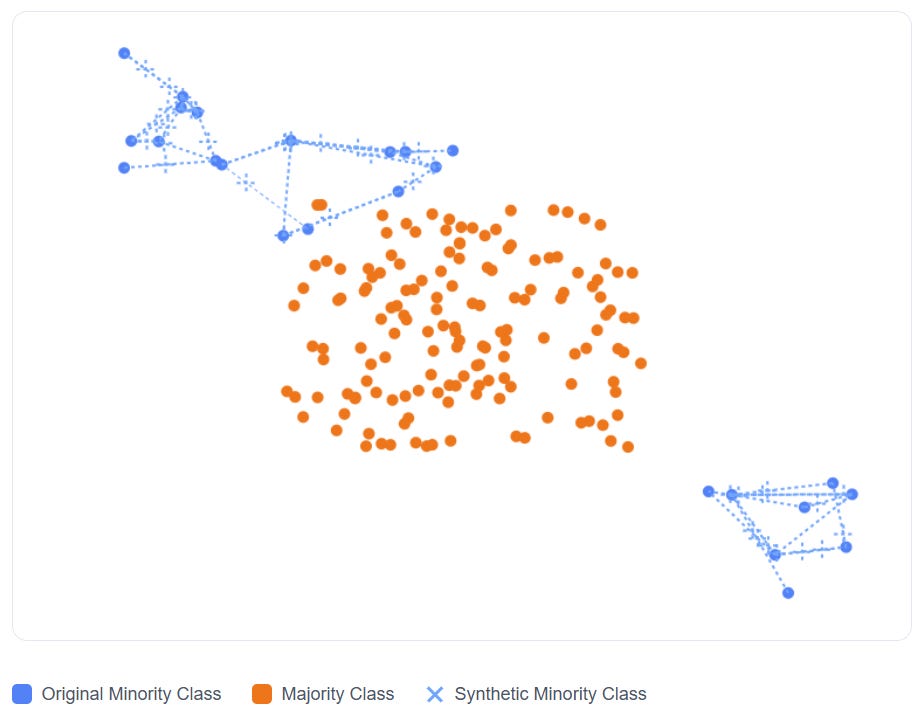
Example: If your dataset has 50 fraud cases and 5,000 normal transactions, SMOTE will “fabricate” additional fraud cases by mixing features of real fraud points.
This approach makes the minority class less sparse and boosts recall in many basic benchmark problems. But in practice, SMOTE can backfire—sometimes badly.
Where SMOTE Fails (and Why People Are Moving On)
Despite its cleverness, SMOTE introduces serious risks that many real-world ML teams can’t afford to take.
1. It Amplifies Noise
SMOTE blindly interpolates data—even around mislabeled or noisy points. This means if your dataset has a single incorrect label, SMOTE can multiply that error.
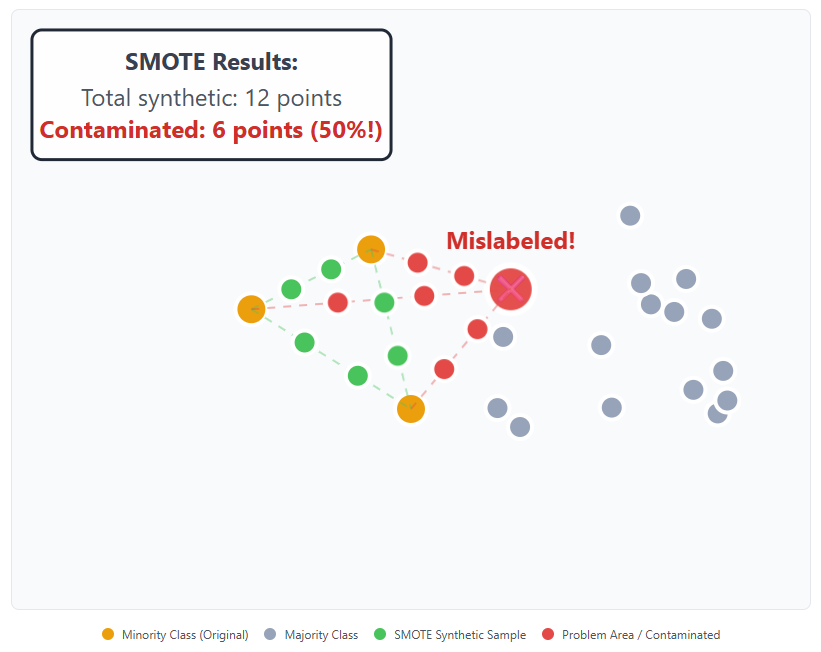
Example: Imagine a cancer dataset with one misclassified benign tumor labeled as malignant. SMOTE will generate several new "malignant" samples based on this wrong example, effectively fabricating a fake region of cancer data. The model then learns to recognize this region as high-risk, skewing predictions.
2. It Encourages Overfitting
SMOTE’s synthetic points are very close to their original counterparts. In small or low-variance feature spaces, this creates tight clusters that the model can memorize instead of generalizing.
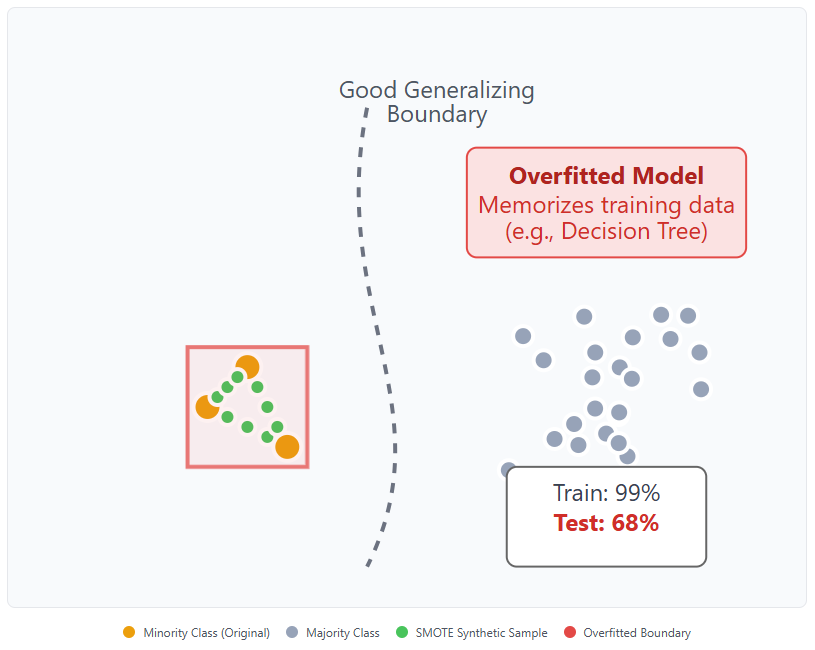
Especially risky with:
Decision Trees and Random Forests (which are prone to overfitting small variations)
Shallow neural networks
Any model trained on small datasets
The result is deceptively good training scores—and disappointing real-world performance.
3. Unrealistic or Physically Impossible Samples
SMOTE doesn't understand domain logic. It interpolates linearly between feature values, regardless of their semantic or physical meaning.

Example: If one diabetes patient is aged 17 and another is aged 80, SMOTE might generate a 48.5-year-old patient with a strange mix of symptoms, treatments, and health markers. In the real world, such a profile may be impossible—or at the very least, misleading.
This is especially problematic in regulated industries like:
Medicine
Finance
Legal or compliance-related analytics
4. It Ignores the Majority Class
SMOTE only looks at the minority class when generating new samples. If some minority points are close to majority regions, SMOTE will still generate samples there—even if it means overlapping the majority class.
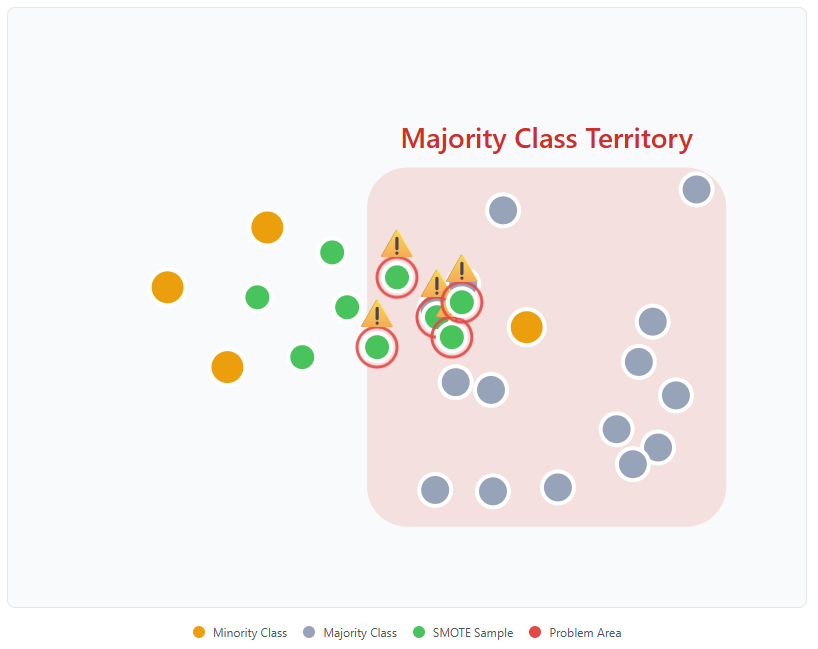
What happens then?
Decision boundaries shift incorrectly
The model starts confusing the classes
False positives go up significantly
This is a classic case of synthetic data introducing noise instead of clarity.
🚀 DeepSeek in Production Summit

Unlock the power of open-source LLMs on Saturday, August 16 — packed with expert talks, hands-on workshops, and real-world deployment tips. Perfect for Gen AI devs, ML engineers, and tech leaders.
💡 Fine-tune with LoRA + Unsloth, dive into FP8 & MoE, and learn from top minds in the field.
🎟 50% off with code: DAV50 — don’t miss it!
🔗 Register now and supercharge your AI stack.
Where SMOTE Fails Most: Some Real-World Domains
Some of SMOTE’s most glaring limitations become obvious when it's applied to high-stakes, real-world domains. These aren’t just academic concerns—they’re production-breaking issues.
Fraud Detection
Fraud cases are rare and often very different from each other. There’s no consistent pattern to interpolate between. But SMOTE assumes there is.
Why it fails:
It blends unrelated fraud types into fake ones that never happened.
The model learns from these made-up examples and starts making wrong predictions.
The result would be more false alarms and worse detection of real fraud.
Example:
One fraudster uses stolen credit cards, another abuses return policies. SMOTE mixes them into a new “fraud” case that’s unrealistic—and confuses the model.
Credit Risk
People who default on loans are very different from each other. SMOTE tries to average these profiles, but the result doesn’t match any real person.
Why it fails:
It creates borrowers who fall between actual categories.
Risk models then misjudge real applicants, especially near decision thresholds.
Example:
Mixing a 22-year-old gig worker with no credit history and a 60-year-old retiree with long credit history creates a fake profile that isn’t helpful—and may mislead the model.
“Imbalance Isn’t a Problem”—The Counter-Argument
Not every team treats an uneven class ratio as something that must be “fixed.” A growing camp of practitioners and researchers argues that the real issue is measurement, not data composition. Here are the pillars of that view:
Probabilistic models still rank well: Algorithms such as logistic regression, gradient-boosted trees, and modern neural nets learn log-odds; class prevalence mainly shifts the intercept, not the feature weights. They can therefore separate positives from negatives even when the positives are rare.
Use metrics that ignore prevalence: ROC-AUC, AUROC, and similar ranking metrics are mathematically independent of base rates. If retrieval is the goal, a low positive rate does not inherently hurt these scores. (For alerting tasks where precision matters, PR-AUC is the better choice.)
Just move the threshold: When probabilities are calibrated, you can pick a cutoff that reflects real-world costs or the true base rate—no resampling required. Threshold tuning is a first-class lever.
Oversampling can break calibration: Large simulation studies show that synthetic or random resampling often inflates predicted risk and can be hard to recalibrate afterward. If probability estimates drive decisions, it may be safer to leave the distribution untouched.
Lighter-weight fixes usually suffice: Class-weighted loss functions, focal loss, or a simple
scale_pos_weightparameter in gradient-boosting libraries often out-perform naive oversampling while preserving calibration.
When rarity does hurt:
If positives are extremely scarce and heterogeneous, anomaly-detection methods (Isolation Forest, One-Class SVM, autoencoders) still make sense.
If your evaluation metric is raw accuracy, switch to one that reflects class costs instead of changing the data.
If gradients vanish in deep learning, apply focal or class-balanced loss before considering synthetic data.
The takeaway: many “imbalanced” problems are solvable by smarter metrics, calibrated probabilities, and cost-sensitive objectives—without fabricating any new examples.
🎓 Two Paths to Mastering AI*
👨💻 Build and Launch Your Own AI Product
Full-Stack LLM Developer Certification
Become one of the first certified LLM developers and gain job-ready skills.
🎯 Finish with a project you can pitch, deploy, or get hired for
🛠️ 90+ hands-on lessons | Slack support | Weekly updates
💼 Secure your place in a high-demand, high-impact GenAI role
🔗 Join the August Cohort – Start Building
💼 Lead the AI Shift in Your Industry
AI for Business Professionals
No code needed. Learn how to work smarter with AI in your role.
✅ Build an “AI-first” mindset & transform the way you work
🔍 Learn to implement real AI use cases across your org
🧠 Perfect for managers, consultants, and business leaders
🔗 Start Working Smarter with AI Today
📅 August Cohorts Now Open — Don’t Wait
🔥 Invest in the skillset that will define the next decade.
*Sponsored: by purchasing any of their courses you would also be supporting MLPills.
Modern Alternatives to SMOTE
Today’s ML workflows have matured. Rather than generating synthetic samples, most practitioners use more robust, interpretable, and data-respecting techniques. Here’s what’s replacing SMOTE:
Keep reading with a 7-day free trial
Subscribe to Machine Learning Pills to keep reading this post and get 7 days of free access to the full post archives.