

Issue #103 - Context Engineering

💊 Pill of the Week
Ever feel like your AI assistant has short-term memory loss? You give it a brilliant instruction, it performs well, but two queries later, it has forgotten the entire plan. This is the problem modern AI systems are built to solve. Today’s agents aren’t one-and-done responders—they are designed to plan, use tools, remember past interactions, and evolve. To do this effectively, they need more than a good prompt; they need a well-managed "brain" or workspace.
This is the essence of context engineering: the purposeful design of what an agent knows and when it knows it. Instead of endlessly tweaking a single prompt, you shape the entire information ecosystem the agent operates within. This empowers it to stay coherent, efficient, and reliable over time. As AI luminary Andrej Karpathy aptly puts it, “context engineering is the delicate art and science of filling the context window with just the right information for the next step.”
This guide presents the four essential pillars—Write, Select, Compress, and Isolate—with clear “how-to” steps to make these advanced concepts approachable and immediately actionable.
What Sets Context Engineering Apart from Prompt Engineering?
Think of a master chef. Prompt engineering is like choosing the final, perfect garnish for a dish—it’s the last touch that defines the presentation.
Context engineering, on the other hand, is the entire mise en place: meticulously preparing and organizing all the ingredients, tools, and recipes before the cooking even starts. It’s the broader architecture for the flow of information—memory, retrieved documents, tool outputs, user history—that supports the entire task. This discipline is the engine behind powerful systems like Retrieval-Augmented Generation (RAG), multi-agent orchestration, and long-context management.
The Four Core Pillars
Before we dive into the mechanics, think of the four pillars as the blueprint for an AI’s cognitive workspace. Each one solves a specific challenge in how an agent manages, filters, condenses, and protects its knowledge over time. Together, they form a repeatable framework you can apply to any domain—whether you’re building a customer support bot, a financial analyst assistant, or, in our example, a medical AI supporting doctors in a busy hospital.

In this guide, we’ll follow that doctor’s assistant scenario from start to finish, showing exactly how Write, Select, Compress, and Isolate work in practice. You’ll see how an AI can listen to consultations, recall past visits, condense years of records, and coordinate with other specialized agents—without losing focus or spilling irrelevant details into the wrong place. By the end, these principles will feel less like abstract concepts and more like practical tools you can implement immediately.

1. Write — Building a Persistent Memory
Goal: Give the agent a reliable long-term memory that exists outside any single prompt, allowing it to recall critical information across sessions.
How to Do It:
Use a Scratchpad for Working Memory: During a task, the agent should maintain a lightweight log of its "thoughts." This includes its chain-of-thought reasoning, intermediate conclusions, failed attempts, and key data points. This scratchpad is its short-term memory.
Create Summaries for Long-Term Recall: At the end of a session or after reaching a key milestone, the agent should condense the critical decisions, outcomes, and learnings from its scratchpad into a concise summary.
Tag and Store for Reuse: Save these summaries with clear metadata identifiers (e.g.,
project_id,user_id,task_name,date). This turns scattered insights into a searchable knowledge base.
Example in Action:
A doctor's AI assistant listens during a patient consultation.
Scratchpad Entry:
"Patient reports sharp chest pain. BP is 140/90. EKG shows minor arrhythmia. Initial thought: possible anxiety. Ruled out after patient mentioned recent strenuous activity. New thought: muscular strain. Plan: order chest X-ray to be safe."Final Summary (Written to Memory):
{"patient_id": "HN45-7B", "date": "2025-08-09", "encounter_type": "consult", "summary": "Patient presented with chest pain. EKG showed mild arrhythmia. Suspected muscular strain post-activity. Ordered chest X-ray as a precaution."}


Clinical implementation: When Patient HN45-7B returns for follow-up, the AI assistant immediately recalls the previous chest pain episode, the suspected muscular strain diagnosis, and the pending X-ray results. The doctor can build on this context rather than starting from scratch, ensuring continuity of care.
2. Select — Delivering the Right Information at the Right Time
Goal: Avoid overwhelming the agent with irrelevant data ("contextual noise"). By feeding it only narrowly relevant information, you sharpen its focus and accelerate its reasoning.
How to Do It:
Tag Your Writes Meticulously: Good selection starts with good writing. Every piece of memory should be labeled with descriptive tags (
topic: "billing",stage: "onboarding",user_id: "user_123").Filter First, Then Rank: Before feeding information to the agent, retrieve a pool of potentially relevant memories using tags. Then, rank these candidates using semantic similarity to find what’s conceptually closest to the current query, not just what matches keywords.
Inject Minimally and Precisely: Only the top-ranked, most relevant snippets should be injected into the agent’s context window. Resist the urge to include extra information "just in case."
Example in Action:
A doctor is seeing a patient who complains of a severe headache. The AI assistant needs to provide the most relevant history.
Action: The system queries the patient's record for entries tagged
patient_id: "HN45-7B"andtopic: "neurology"orsymptom: "headache".Selection: It retrieves ten past visit summaries. Using semantic search, it ranks a note from two years ago—
"Patient diagnosed with migraines, prescribed Sumatriptan, reported effective"—as the #1 most relevant snippet, above unrelated notes about a sprained ankle and a flu shot.Injection: Only that single, crucial sentence is added to the doctor's dashboard, immediately reminding them of the patient's history with migraines.
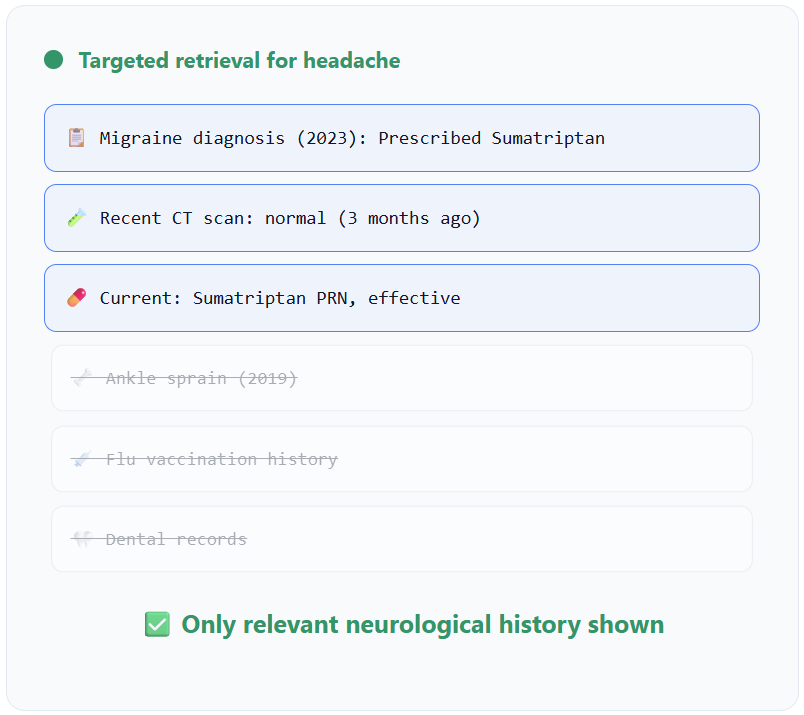
Semantic selection in action: Patient complains of severe headache. The AI queries records tagged with patient_id: "HN45-7B" and filters for neurological/headache keywords. Using semantic search, it ranks the 2-year-old migraine diagnosis as #1 most relevant, immediately surfacing the successful Sumatriptan treatment—critical context the doctor needs.
🎓 Two Paths to Mastering AI*
👨💻 Build and Launch Your Own AI Product
Full-Stack LLM Developer Certification
Become one of the first certified LLM developers and gain job-ready skills:
Build a real-world AI product (like a RAG-powered tutor)
Learn Prompting, RAG, Fine-tuning, LLM Agents & Deployment
Create a standout portfolio + walk away with certification
Ideal for developers, data scientists & tech professionals
🔗 Join the August Cohort – Start Building
💼 Lead the AI Shift in Your Industry
AI for Business Professionals
No code needed. Learn how to work smarter with AI in your role:
Save 10+ hours/week with smart prompting & workflows
Use tools like ChatGPT, Claude, Gemini, and Perplexity
Lead AI adoption and innovation in your team or company
Includes role-specific modules (Sales, HR, Product, etc.)
🔗 Start Working Smarter with AI Today
📅 August Cohorts Now Open — Don’t Wait
🔥 Invest in the skillset that will define the next decade.
*Sponsored: by purchasing any of their courses you would also be supporting MLPills.
3. Compress — Maximizing Information Density
Goal: Preserve the essence of information while trimming its size to fit within the model’s finite context window (i.e., token limit). This keeps long-running tasks coherent and affordable.
How to Do It:
Use Rolling Summaries: In an ongoing conversation, don't keep the entire raw transcript. After every 3-5 turns, create a summary of what was discussed and decided, then discard the original messages.
Chunk, Select, then Condense: For long documents, don't summarize the whole thing. Instead, break the document into smaller chunks, use the Select pillar to identify the most relevant chunks, and then summarize only those key parts.
Enforce Structured Formats: Ask the model to return summaries in a predictable format like JSON or markdown bullet points. This is far more token-efficient than prose. For example:
"Summary: [decision]. Next Steps: [action items]. Open Questions: [unresolved points]."
Example in Action:
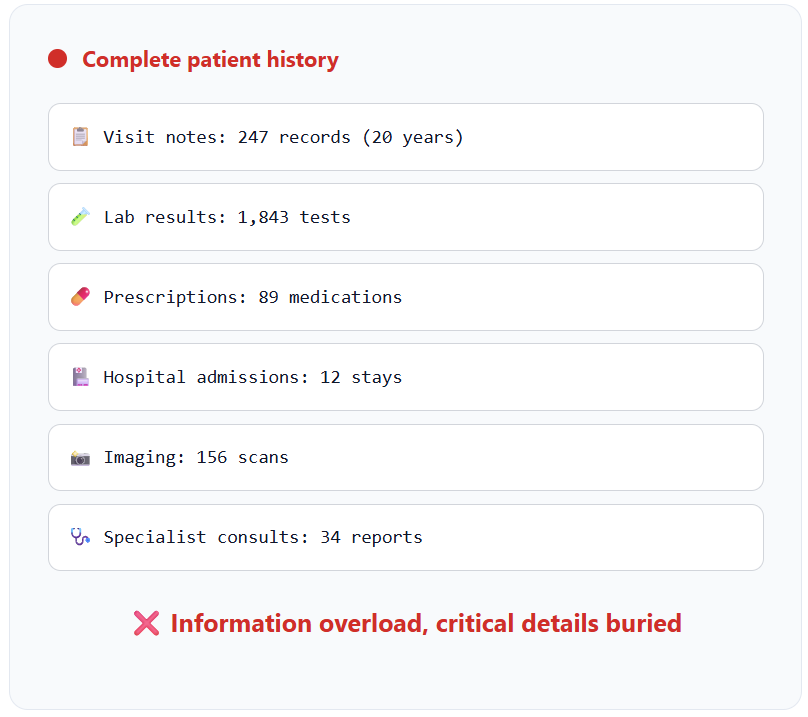
A doctor needs a quick overview of a new patient with a 20-year medical history before walking into the exam room.
Before Compression (Raw Log): A 50-page digital file with hundreds of visit notes, lab results, and prescriptions.
After Compression (Structured Summary): The AI assistant processes the entire file and generates a concise, structured brief for the doctor's tablet:
JSON
{
"patient_id": "HN45-7B",
"active_conditions": ["Hypertension (controlled)", "Migraines"],
"key_allergies": ["Penicillin"],
"major_surgeries": ["Appendectomy (2015)"],
"recent_meds": ["Lisinopril", "Sumatriptan (as needed)"]
}
The doctor gets the critical information in seconds.
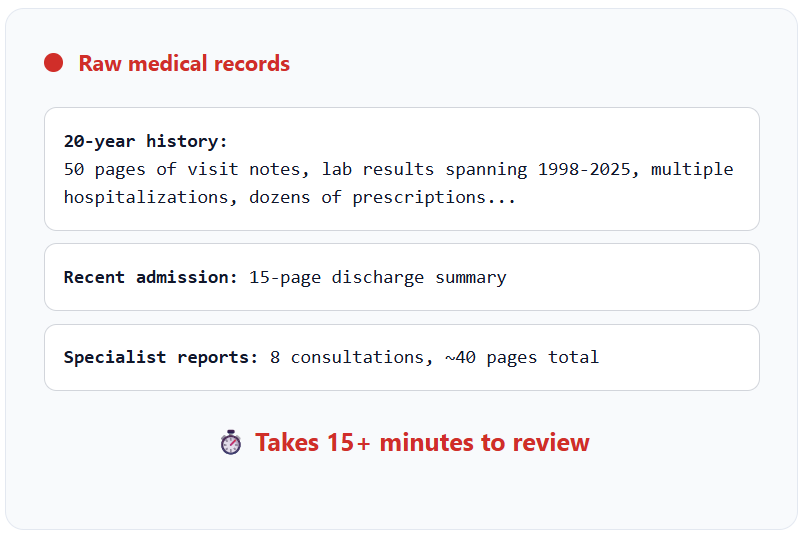

Hierarchical compression: Before entering the exam room, the doctor receives an AI-generated brief that distills 20 years of medical history into a structured JSON summary. Active conditions, allergies, and current medications are immediately visible on their tablet—no critical information is missed, no time is wasted.
4. Isolate — Preventing Cross-Contamination
Goal: Keep context clean and task-aligned, especially in systems with multiple agents or parallel tasks. This prevents one agent's "thoughts" from bleeding into another's, ensuring predictable and reliable behavior.
How to Do It:
Keep reading with a 7-day free trial
Subscribe to Machine Learning Pills to keep reading this post and get 7 days of free access to the full post archives.