

Issue #113 - Interpreting XGBoost predictions

💊 Pill of the Week
Modern machine learning models are often capable of impressive predictive performance, but they are also criticised for being opaque. Understanding not only what a model predicts but also why it predicts it is essential, especially in domains where transparency matters.
This guide walks you through both sides of the process:
Understand why interpretability matters and how it complements predictive performance.
Learn how XGBoost works at a high level before touching any code.
Train an XGBoost model step by step using the diabetes dataset.
Extract SHAP values directly from XGBoost (no external shap library needed).
Break down predictions for individual samples using local interpretation.
Identify the most influential features across the whole dataset using global interpretation.
The aim is to give you a complete workflow that explains the theory, shows the code, and clarifies the interpretation of both local and global feature importance.
💎At the end you will find the full code!
1. Understanding the Model: What XGBoost Actually Does
Before diving into code, it is worth understanding the model you are about to train.
We covered this model long time ago, here is the article:

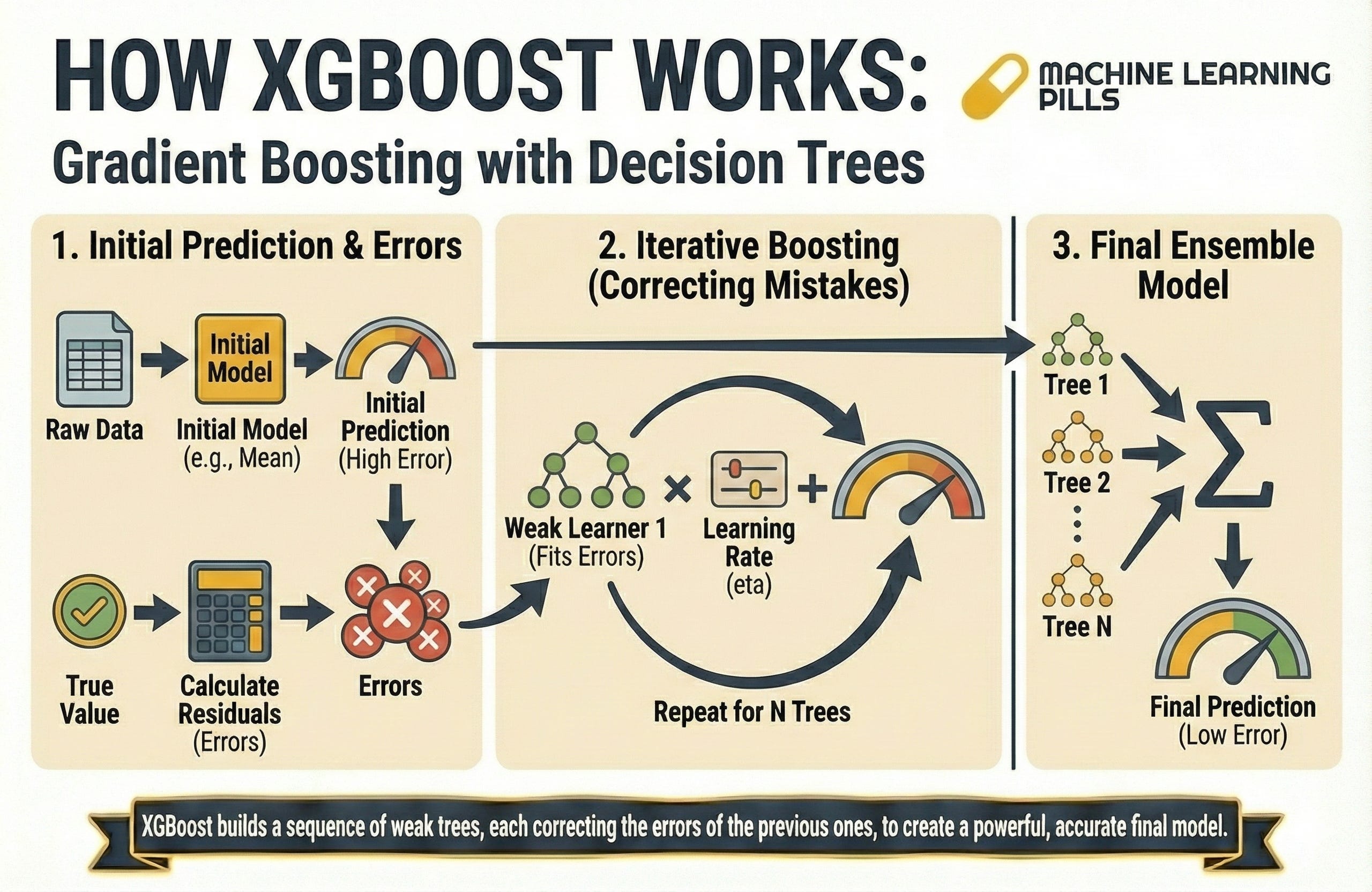
1.1 The Idea Behind XGBoost
XGBoost stands for Extreme Gradient Boosting. It is part of a family of boosting algorithms that build many small decision trees in sequence. Each tree is deliberately weak. Instead of trying to solve the problem outright, it focuses on correcting the errors of the trees that came before it.
The process looks like this:
The first tree makes an initial prediction.
The second tree identifies what the first tree got wrong and attempts to correct those specific errors.
The third tree corrects the mistakes of the second, and so the sequence continues.
By the time you reach the hundredth tree, you have a collection of individually weak learners whose combined output produces a strong predictive model. The final prediction is simply the sum of all tree outputs.
1.2 What We Are Trying to Predict
In this guide, the objective is to predict disease progression using the well-known diabetes dataset from Scikit-Learn. The model will receive numerical features such as age and BMI and produce a continuous prediction representing disease progression.
2. Training an XGBoost Model Step by Step
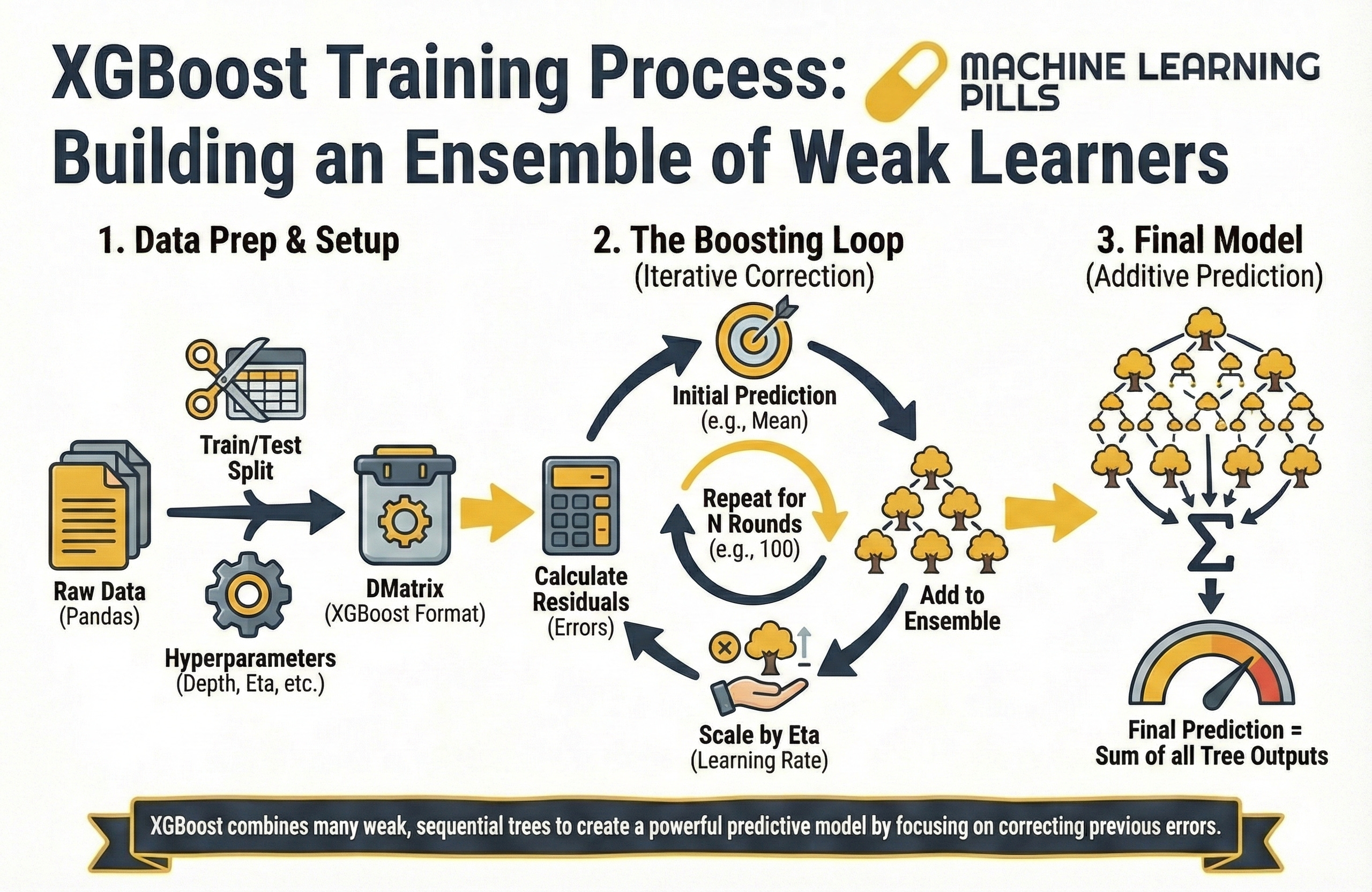
Let us now turn these ideas into code.
import xgboost as xgb
import pandas as pd
import numpy as np
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
# 1. Load and Prepare Data
data = load_diabetes()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = data.target
# Train-test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 2. Convert to DMatrix (XGBoost’s internal format)
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
# 3. Model hyperparameters
params = {
‘objective’: ‘reg:squarederror’,
‘max_depth’: 4,
‘eta’: 0.1,
‘verbosity’: 0
}
# 4. Train the model
model = xgb.train(params, dtrain, num_boost_round=100)
At this point, your model is fully trained and ready to make predictions. You can see this process in a more visual way below:
3. Understanding the Explanation: What SHAP Values Represent
Training a model is only one part of the job. It is equally important to understand why the model behaves the way it does.
3.1 The SHAP Concept
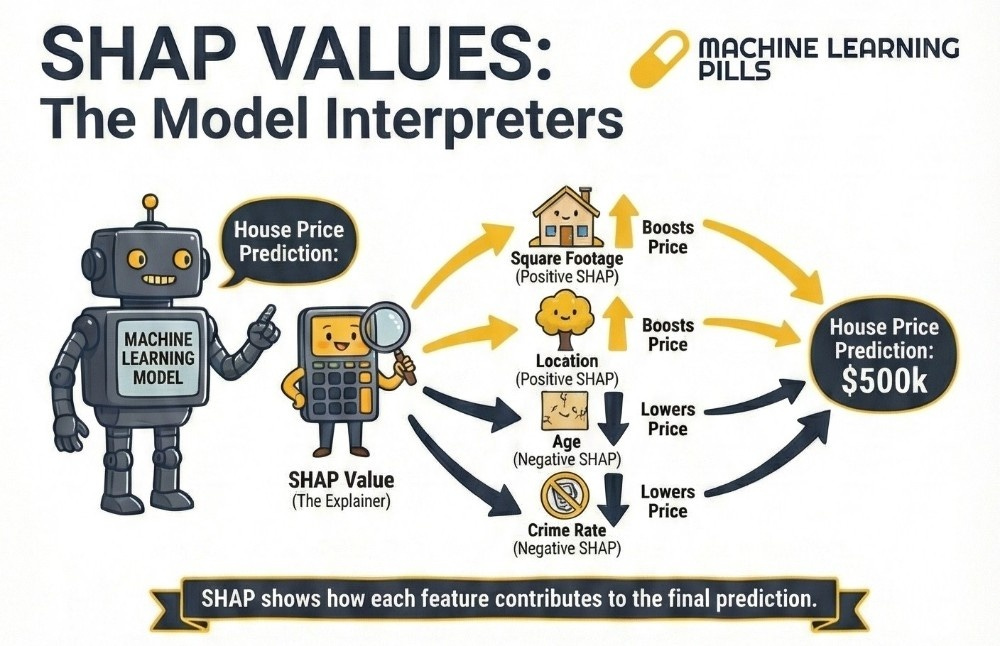
SHAP stands for SHapley Additive exPlanations. It originates from cooperative game theory, where multiple players work together to achieve a result and the aim is to determine the contribution of each player.
We covered this in the past, here is a refresher:


In the context of machine learning:
The players are the features such as BMI, age or blood pressure.
The game is the prediction task.
The payout is the final prediction.
The key question is: How much did each feature contribute to the prediction compared with the average prediction of the model?
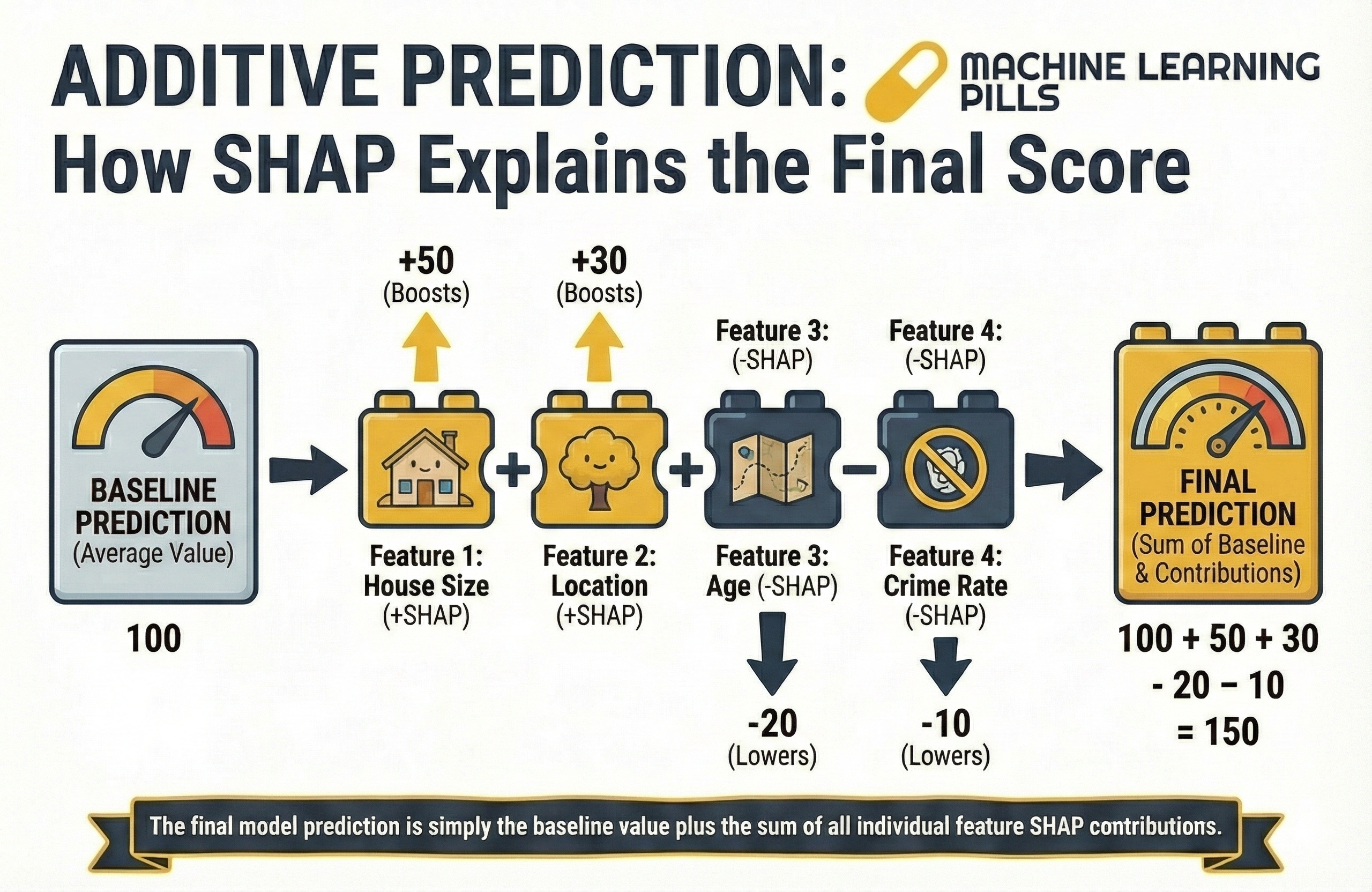
3.2 The Additive Structure
For any given sample, the prediction can be decomposed as:
Prediction = Baseline + Sum of SHAP contributions
Where:
The baseline is the average model prediction across the training dataset.
Each SHAP value explains how much a feature pushes the prediction higher or lower relative to that baseline.
📖 Book of the Week
If you’re building enterprise-grade GenAI systems or leading AI adoption inside complex organisations, this is one of the most strategic and practical guides you can pick up.
“LLMs in Enterprise: Design strategies, patterns, and best practices for large language model development” by Ahmed Menshawy & Mahmoud Fahmy

💡 A clear, structured playbook covering the full lifecycle of enterprise LLM systems — from foundations to advanced design patterns, optimisation techniques, deployment architectures, governance, and real operational concerns like evaluation and cost control.
What makes it stand out
It delivers a pattern-driven approach to building reliable, scalable, and responsible LLM applications. Instead of surface-level demos, you get concrete strategies for real-world challenges: scaling models, integrating RAG, improving reliability, ensuring transparency, and managing LLM systems in production.
You will learn to:
✅ Apply proven design patterns for integrating LLMs into enterprise systems
✅ Scale, deploy, and optimise LLM applications effectively
✅ Use fine-tuning, contextual customisation, and RAG to boost performance
✅ Develop robust data strategies that improve quality and reliability
✅ Implement advanced inferencing and optimisation patterns
✅ Evaluate and monitor LLMs with enterprise-ready frameworks
✅ Ensure security, compliance, and responsible AI practices
✅ Stay ahead with insights on multimodality and emerging GenAI trends
If you’re serious about moving from prototypes to scalable, low-risk enterprise AI solutions, this book provides the guidance and patterns to get there.
4. Extracting SHAP Values Using Only XGBoost
A common misconception is that SHAP values require the external shap library.
Keep reading with a 7-day free trial
Subscribe to Machine Learning Pills to keep reading this post and get 7 days of free access to the full post archives.