

Issue #133 - AI-Assisted Coding: From Notebooks to Production

💊 Pill of the week
Most people who come to coding through data science learn to treat code as a means to an end. You write a notebook, clean a dataset, generate a chart, train a model, export the result, and move on. The code matters, but mostly because of what it produces.
That mental model works well for analysis. It breaks down when you start building software.
Once you begin using AI to ship applications, internal tools, automations, or production systems, the code is no longer just a path to an output. The code itself becomes the thing people rely on. It has to keep running after you close the laptop. It has to handle bad inputs, strange users, broken APIs, and future changes you cannot predict yet.
This is the first mindset shift for the data scientist becoming a software builder: not all code has the same job.
The two species of code
There are two kinds of code in the world, and they look almost identical on the screen.
One produces a result.
The other is the result.
The difference is not in the syntax. It is in what happens after you stop watching.
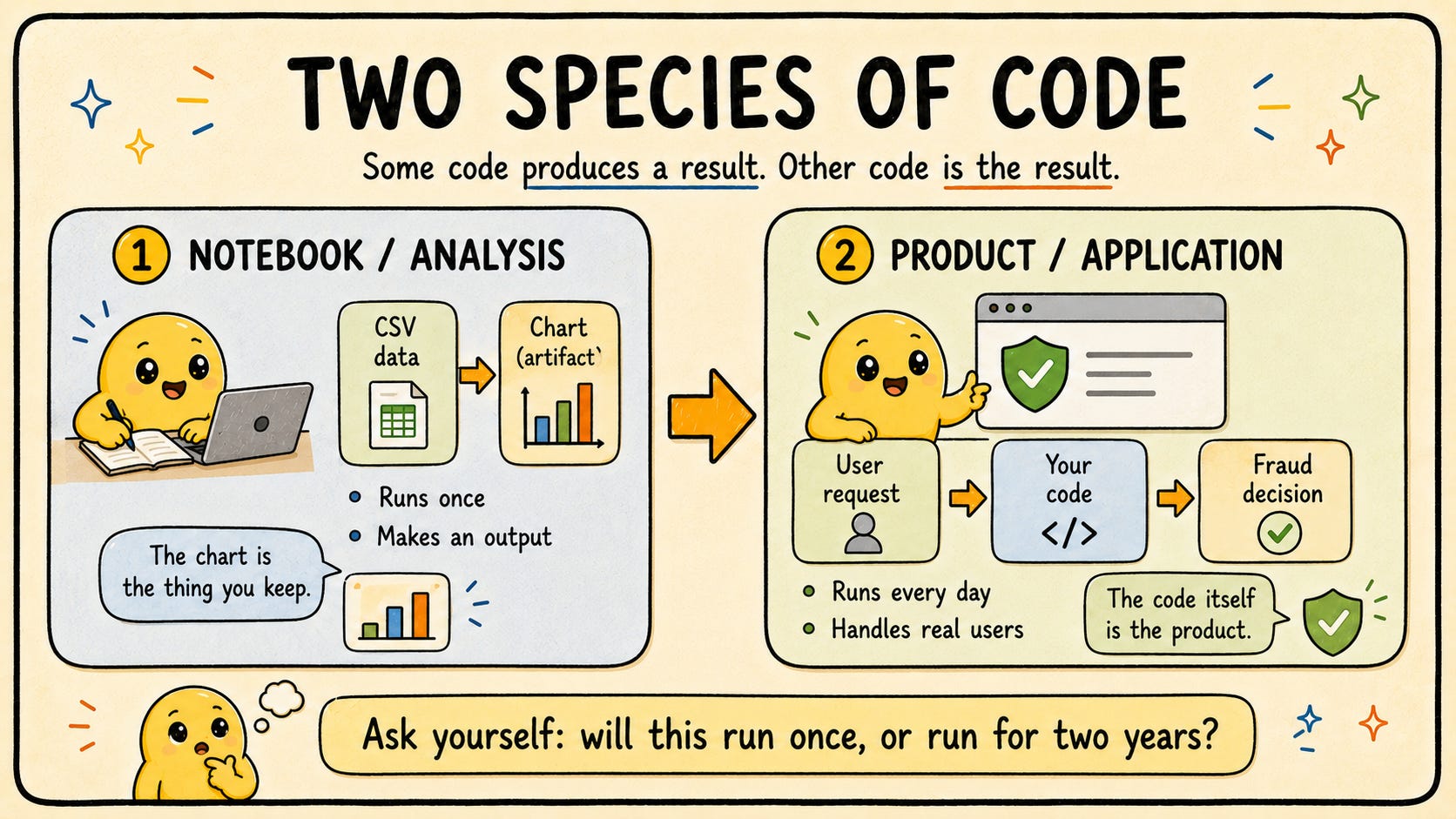
A notebook cell that loads a CSV, joins it with another table, and outputs a chart is code that produces a result. Once the chart exists, the code has done its job. If you delete the cell, nothing real changes. The artifact you cared about, the chart, is already out the door.
A function inside a deployed application that loads a user’s transactions, scores them for fraud, and returns a decision is code that is the result. You cannot delete it. It runs thousands of times a day. Each run matters. Each run might be the one where a bug costs someone real money. The code is not a tool that made something. The code is the thing that exists.
If you have spent years in data science, you have internalized the first model so deeply that the second one feels strange. Software engineers have the opposite problem: they over-engineer for permanence when permanence is not needed. The vibe coder coming from DS has to learn to switch modes consciously, because the AI assistant cannot tell which mode you are in. It will happily produce code that runs once when you needed code that runs forever, and the failure mode is invisible until the production incident.
Why this matters more with AI in the loop
When you write code by hand, your fingers have to type every line. That friction acts as a natural slowdown. You think about each function because you have to write it. You spot the missing error handler because you are looking at the empty space.
When you vibe code, the AI removes that friction. It writes 200 lines in 10 seconds. The code looks complete. It even runs. But it has the shape of a script, not the shape of a system. It assumes inputs are clean, files exist, networks respond, users behave. None of that is true in production.
The shift you need to make is: do not let the AI’s confidence become your confidence. The AI does not know whether this code will run once or run for two years. You do. That knowledge has to shape every prompt you write and every output you accept.
The three key principles
1. Understand every line you commit
The test is simple: pick any function in your codebase and explain in plain language what it does, why it does it that way, and what happens when its inputs are empty, malformed, or hostile. If you cannot, you are renting that code from the AI. The rent comes due the first time it breaks, usually at the worst possible moment.
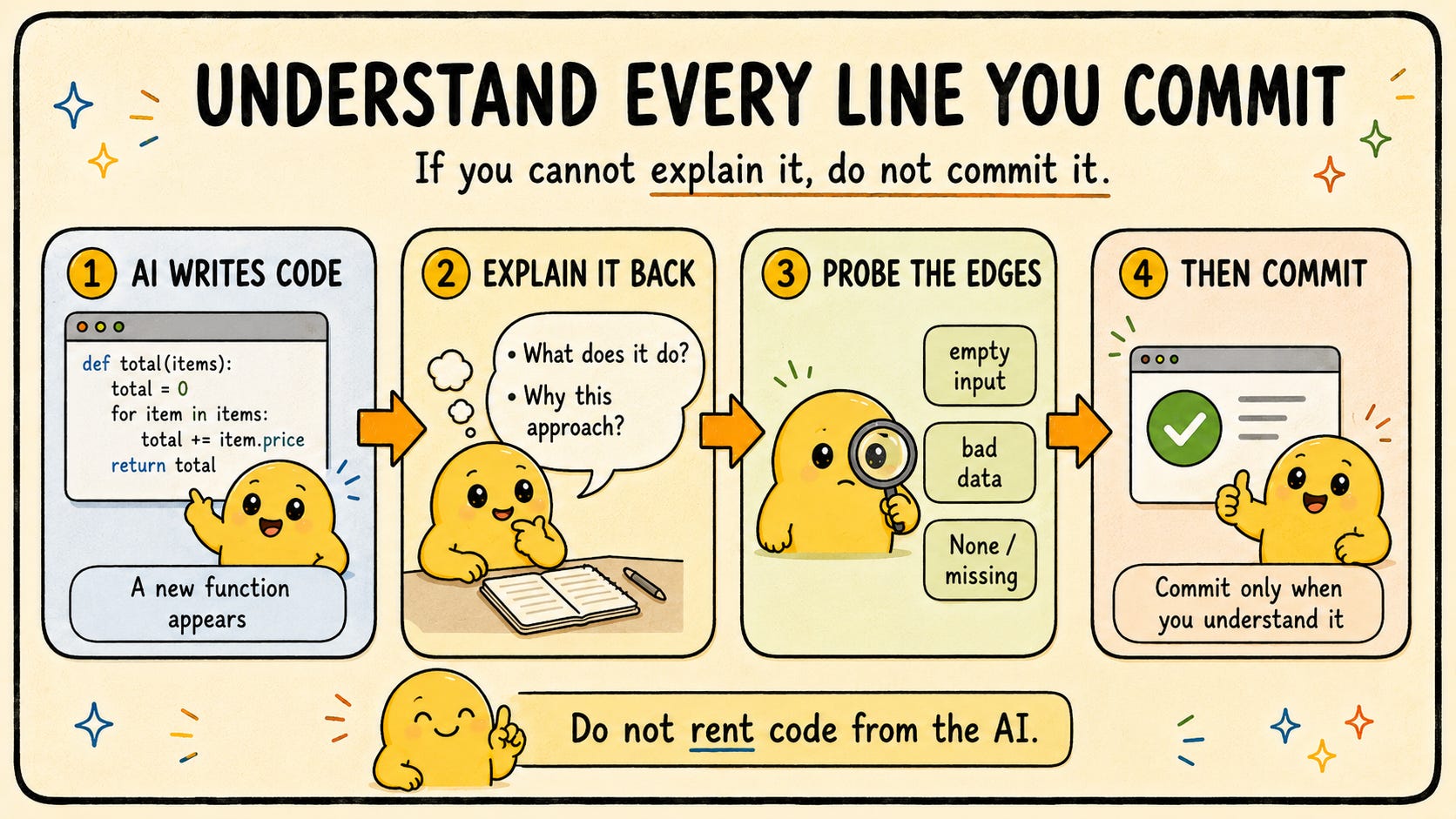
In practice this means:
After the AI produces a function, ask it to explain the function back to you. Then ask follow-up questions. “Why did you choose a list instead of a set here?” “What happens if
user_idisNone?” “Why is this in a try/except instead of a check?”When something looks unusual, find out why before you accept it. “Magic” code is the highest-bug-density code there is.
If you do not understand a library being used, look up the docs or ask the AI to walk you through it. Do not let imports you cannot explain enter the codebase.
This sounds slow. It is slow at first. Within a few weeks it becomes automatic, and the code you ship is dramatically better.
2. Ship in small slices
Notebooks teach you to think top-to-bottom. You write cell 1, then cell 2, then cell 3, and they run in order. When something breaks, you re-run from the top.
Software does not work that way. You cannot re-run a production system from the top. You change one thing, then another, then another. Each change is reversible only if you can identify it and only it.
The discipline is to commit often, in small logical chunks.
👎The wrong way:
Write 600 lines of code over two hours. Commit once at the end with message “build user dashboard.”
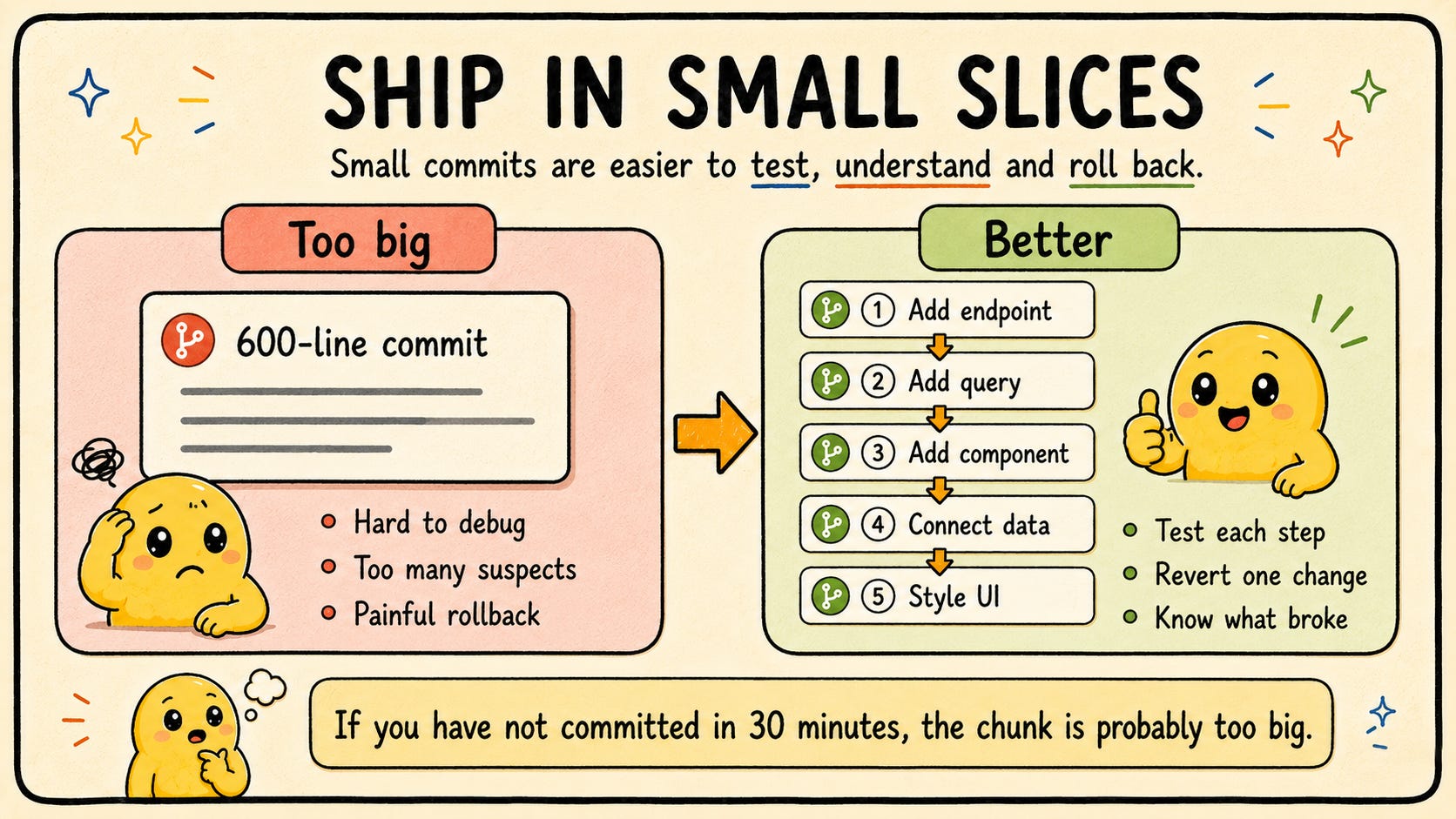
When that commit breaks something, you have 600 lines of suspects.
👍The right way:
Write the API endpoint. Test it. Commit. (”add GET /users endpoint”)
Write the database query. Test it. Commit. (”add user query with pagination”)
Write the frontend component. Test it. Commit. (”add UserList component”)
Wire up data fetching. Test it. Commit. (”connect UserList to /users endpoint”)
Style it. Test it. Commit. (”style UserList with Tailwind”)
Five small commits, each runnable, each reversible. When the fourth commit breaks something, you know exactly which one. You revert it, fix it, re-commit. The other four are safe.
This habit is unnatural at first. Most DS folks have never made more than three commits in a day. Aim for ten. Aim for twenty. The smaller, the better.
