

Issue #135 - AI Agent Evals: What to Measure Beyond the Final Answer
A Practical Evaluation Framework

💊 Pill of the Week
You built an agent. It runs. It calls tools. It produces outputs. You eyeball a few runs, they look fine, and you ship.
Three days later it fails silently on 30% of production tasks. You have no idea why.
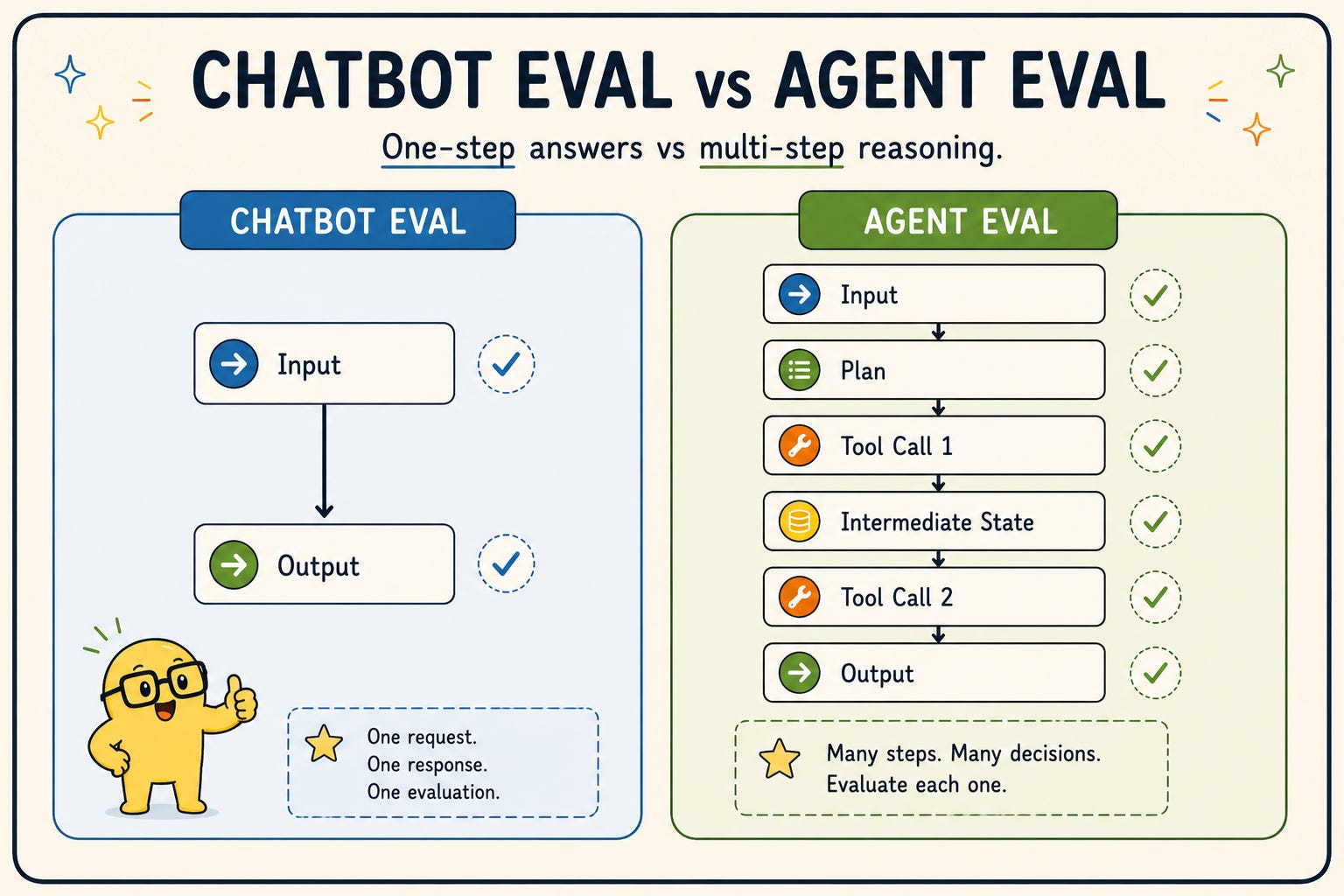
This is what happens when you evaluate agents the same way you evaluate chatbots. A chatbot eval is simple: does the output match intent? One turn, one response, done. Agents are a different animal entirely. They plan, call tools in sequence, branch on intermediate results. A single bad decision on step 3 of 9 can cascade into a completely wrong final answer, and the final output still looks plausible on the surface.
Standard evals miss this entirely. Today I introduce you a framework that does not.
Paid subscribers get one extra: an advanced extension of this article will be going out this Wednesday. After that date it’s gone for anyone not already subscribed. It will be available for only 24h!
This follow-up expands the original framework with the production checks most teams miss: repeated-run reliability, end-state verification, policy compliance, production trace review, and faithful use of tool outputs.
Don’t miss it!
Why chatbot evals break for agents?
The difference comes down to what you are actually measuring.
A chatbot eval measures input → output quality. One turn, one response, one score.
An agent eval has to measure input → trajectory → tool calls → intermediate state → final output → cost → latency → failure modes. It runs across multiple turns, and failure can happen at any one of them in ways that do not show up in the final output.
The cost signal is different too. Chatbot cost is token count. Agent cost is token count plus tool calls plus retries plus latency across every step.
That middle section (trajectory, tool calls, intermediate state) is where agents die in production. You can have a perfect final answer produced via a completely wrong reasoning path. That path will fail the moment conditions change slightly. You can have a correct-looking output that cost $0.80 and took 45 seconds when it should cost $0.04 and take 4.
The eval has to see all of it.
The seven dimensions of agent evaluation
What is an agent eval? An agent eval is a structured test that measures not just whether an agent reached the right answer, but how it got there. It captures the full execution trace (every decision, every tool call, every intermediate state) and scores against predefined criteria across multiple dimensions simultaneously.
Think of it as the difference between grading only a student’s final exam answer versus watching them work through the problem and checking their reasoning at every step.
Agent evaluation is not one metric. A useful eval system scores the agent across seven dimensions:
Task Success Rate: did the agent complete the goal?
Trajectory Evaluation: did it follow the right sequence of steps?
Tool Call Accuracy: did it choose the right tools and pass the right arguments?
Hallucination Rate in Tool Outputs: did it invent or misread intermediate results?
Latency and Cost Per Task: did it stay within production constraints?
Retry and Recovery Behavior: did it handle failures safely?
Human Review and Edge Case Scoring: did it behave well in cases automated checks miss?
Most teams only measure the first one. Production agents need all seven.
🎓 Agentic AI for Production
Most developers hit the exact same wall with Agentic AI: it works beautifully on their local machine, and then completely falls apart in production.
If you’re ready to escape “demo purgatory,” check out Your Path to Agentic AI for Production* by Towards AI and Paul Iusztin.

This isn’t a passive, follow-along tutorial. It’s a hands-on sprint to teach you the system design fundamentals that outlast today’s trending frameworks. You will leave with two fully deployed systems for your portfolio:
An Autonomous Research Agent: Master multi-source data collection, ReAct reasoning loops, and tool orchestration (using Gemini, Perplexity, and Firecrawl).
A Multi-Modal Writing Workflow: Implement evaluator-optimizer patterns and LangGraph orchestration to turn research into publication-ready content.
*by purchasing any of their courses you would also be supporting MLPills.
1. Task Success Rate
This is the only metric most people track. It is necessary but not sufficient.
Task success means: did the agent accomplish the stated goal? Define this precisely before you write a single eval. Vague goals produce vague evals that tell you nothing actionable.
Examples by agent type:
Research agent: did it return the factually correct answer with sources?
Booking agent: was the reservation made with the right parameters (date, seat, name)?
Code-writing agent: does the generated code pass the test suite without modification?
Data extraction agent: were all required fields populated with correct values?
Two variants to track:
Binary success (pass/fail): Clean to compute, easy to track over time. This is your headline number. Did the agent complete the task or not.
Partial credit scoring: The agent got steps 1-4 right but failed on step 5. Score each subtask independently on a 0-1 scale. This is where you diagnose where in the trajectory things break.
Track both. Binary tells you your headline number. Partial credit tells you where to fix things.

2. Trajectory Evaluation
This is the one most teams skip and later regret. It is also the most powerful signal you have.
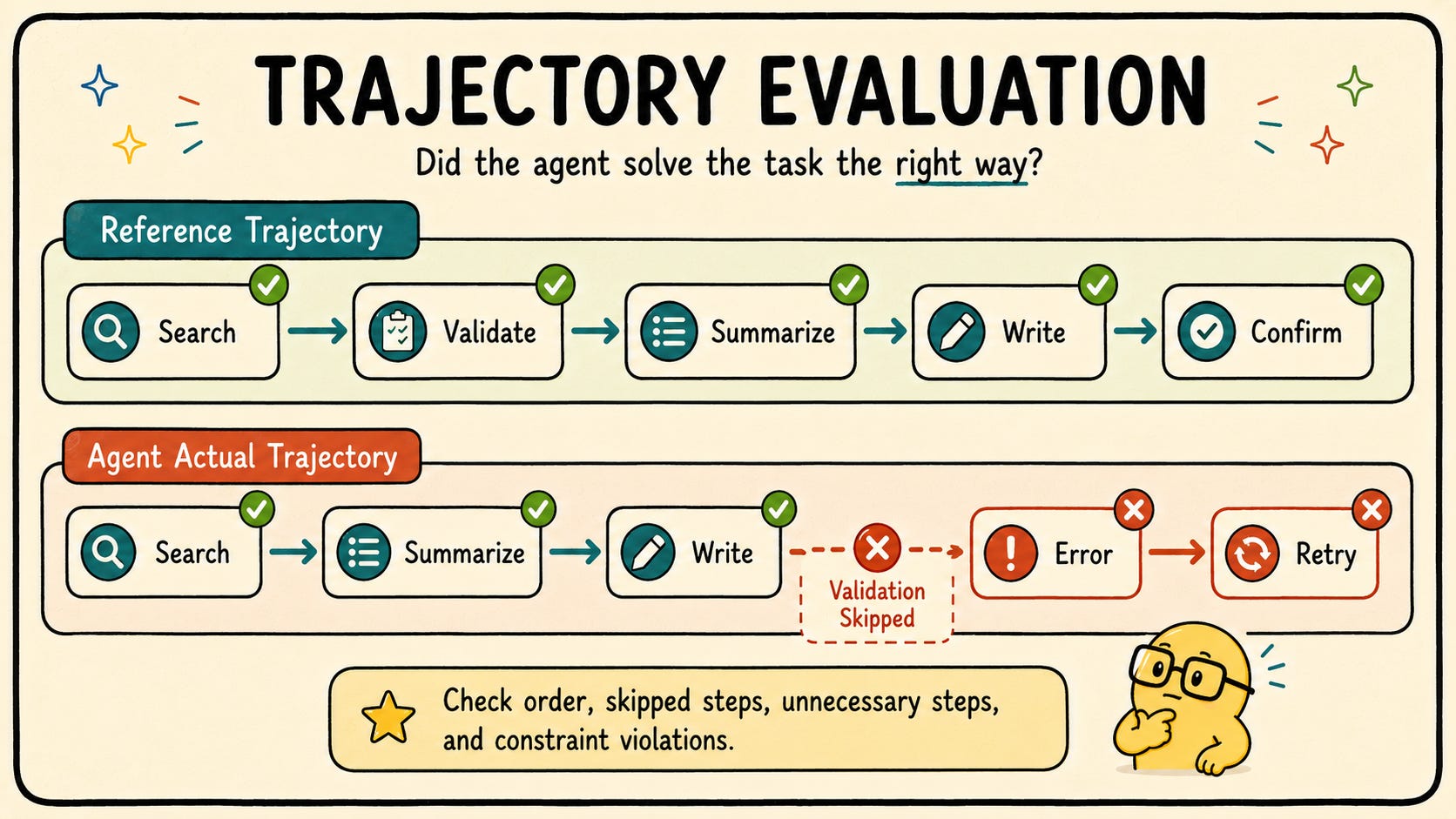
Trajectory: A trajectory is the complete, ordered sequence of steps an agent executed to complete a task: which tools it called, in what order, with what arguments, and what decision it made at each branch point. Two agents can produce the same final answer via completely different trajectories. One will be robust; one will be fragile.
Trajectory eval answers a different question than task success: did the agent solve the problem the right way?
You define a reference trajectory for each test case. Then you compare the agent’s actual trajectory against it. The key signals to check:
Tool call order: Did it search before summarizing? Did it validate before writing? Wrong order often produces right-looking outputs that are brittle in edge cases.
Unnecessary steps: Did the agent call the same tool three times when once was enough? Wasted cost and latency, even if the final answer is correct.
Skipped steps: Did it hallucinate an intermediate result rather than actually retrieving it? This is the silent killer in production.
Branching decisions: When the agent hit an ambiguous state, did it ask for clarification or make an assumption? Was the assumption correct?
Constraint violations: Did the agent ever call a write tool before a read tool? Did it skip a required validation step?
You do not need a perfect match to reference trajectories. You need a similarity score and a set of hard constraints (e.g. “must call validation tool before write tool”). Constraint violations are always a hard fail regardless of what the final output looks like.
3. Tool Call Accuracy
Agents fail at the tool level in two distinct ways and you need to instrument for both separately.
The two failure modes of tool use:
Selection errors: The agent called the wrong tool entirely. Used a web search when it should have queried the internal database. Called the write tool when it should have called read first.
Argument errors: The agent called the right tool but passed wrong arguments. Wrong date format, wrong entity ID, missing required field, hallucinated parameter value.
Argument errors are the sneakier of the two. A web search with a subtly wrong query string will still return results, just bad ones. The agent proceeds as if nothing went wrong. The final output degrades silently. You only catch this in trajectory review.
What to log for every tool call:
Tool name called vs. expected tool name
Argument values vs. expected argument values
Whether the call succeeded, errored, or returned unexpected output
Downstream reasoning: did the agent use the actual return value?
The aggregation trap: Do not only track overall tool accuracy. A 90% aggregate number can hide one specific tool with 50% accuracy that happens to handle your highest-stakes operations. Track accuracy per tool, and rank them by error rate.
4. Hallucination Rate in Tool Outputs
Agents hallucinate differently than chatbots, and in more dangerous ways.
Keep reading with a 7-day free trial
Subscribe to Machine Learning Pills to keep reading this post and get 7 days of free access to the full post archives.