

Issue #90 - Choosing the Right ML Model

💊 Pill of the Week
Selecting an appropriate machine learning model is one of the most crucial decisions in developing AI solutions. This choice can dramatically impact your project's success, affecting everything from prediction accuracy to deployment feasibility. This guide will walk you through the key considerations and provide a structured approach to making this important decision.
Understanding Your Problem Space
Before diving into model selection, it's essential to thoroughly understand the nature of your problem. Machine learning problems generally fall into several broad categories, each suited to different types of models:
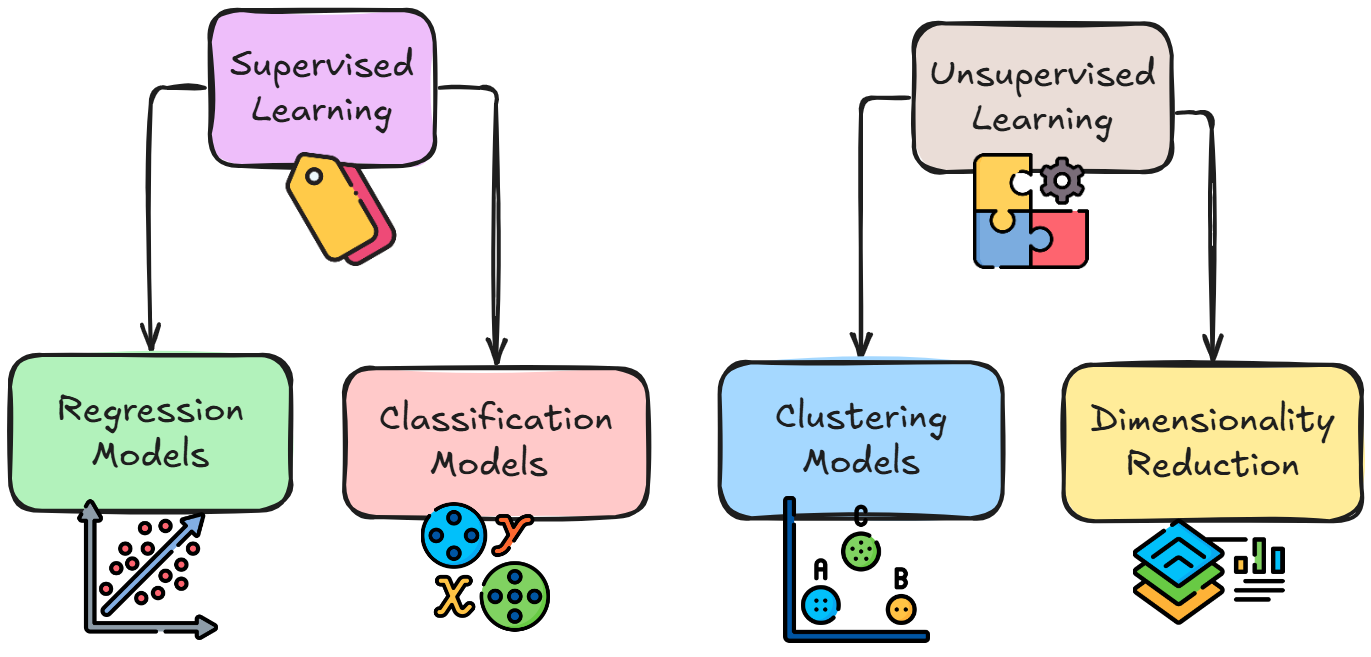
Supervised Learning Problems
In supervised learning, you have labeled data that shows the correct answers your model should predict. These problems further divide into:
Classification Problems: When you need to predict discrete categories or classes, you're dealing with a classification problem. For example, determining whether an email is spam or not spam, or identifying the species of a flower based on its measurements. Classification can be:
Binary (two classes, like spam/not spam)
Multiclass (multiple distinct classes, like different flower species)
Multilabel (items can belong to multiple classes simultaneously, like a movie belonging to both "action" and "comedy" genres)
Regression Problems: These involve predicting continuous numerical values. For instance, predicting house prices, estimating a person's age from a photo, or forecasting sales volumes. The key distinction from classification is that your output exists on a continuous spectrum rather than in discrete categories.
Unsupervised Learning Problems
When working with unlabeled data, you're in the realm of unsupervised learning. Common scenarios include:
Clustering: This involves finding natural groupings within your data. For example, segmenting customers based on purchasing behavior or grouping similar news articles together. The model must discover patterns without being told what patterns to look for.
Dimensionality Reduction: When dealing with high-dimensional data (data with many features), you might need to reduce the number of dimensions while preserving important information. This can help with visualization, computational efficiency, and removing noise from your data.
Data Considerations
The characteristics of your data significantly influence model selection:
Data Volume
The amount of available data affects your model choice in several ways:
Small datasets (hundreds to few thousands of samples) often work better with simpler models that have fewer parameters to learn, such as linear models or decision trees
Large datasets (millions of samples) can support more complex models like deep neural networks, which need substantial data to learn effectively
Very large datasets might require models that can train incrementally, as not all data may fit in memory
Data Quality
Your data's quality characteristics should inform your model selection:
Missing Values Some models handle missing data better than others:
Tree-based models can naturally work with missing values
Linear models typically require imputation strategies
Neural networks usually need complete data or careful handling of missing values
Noise and Outliers Different models have varying sensitivity to noise:
Linear models are highly sensitive to outliers
Tree-based models are more robust to outliers
Ensemble methods can help reduce the impact of noisy data
Feature Characteristics
The nature of your features affects model selection:
Categorical features might need encoding, which can create high-dimensional sparse data
Text data might require specialized models like transformers
Time series data often needs models that can capture temporal dependencies
Image data typically requires convolutional neural networks
Model Properties to Consider
Each model type has distinct characteristics that make it more or less suitable for different scenarios:
Interpretability vs Performance
This common trade-off requires careful consideration:
Linear models and decision trees offer high interpretability but might have lower performance
Neural networks and ensemble methods often provide better performance but are harder to interpret
Some domains (like healthcare or finance) might require interpretable models for regulatory compliance
Computational Requirements
Consider both training and inference costs:
Training time can range from seconds (linear models) to days or weeks (deep learning)
Memory requirements vary significantly between models
Inference speed becomes crucial in real-time applications
Hyperparameter Sensitivity
Some models require more tuning than others:
Linear models often have few hyperparameters
Neural networks have many hyperparameters that significantly impact performance
Ensemble methods usually have moderate hyperparameter sensitivity
🎓Further Learning*
Let us present: “From Beginner to Advanced LLM Developer”. This comprehensive course takes you from foundational skills to mastering scalable LLM products through hands-on projects, fine-tuning, RAG, and agent development. Whether you're building a standout portfolio, launching a startup idea, or enhancing enterprise solutions, this program equips you to lead the LLM revolution and thrive in a fast-growing, in-demand field.

Who Is This Course For?
This certification is for software developers, machine learning engineers, data scientists or computer science and AI students to rapidly convert to an LLM Developer role and start building
*Sponsored: by purchasing any of their courses you would also be supporting MLPills.
⚡Power-Up Corner
To help you make an informed decision, here’s a structured approach to selecting the right machine learning model. This decision-making process ensures you consider key factors such as the availability of labeled data, the type of problem, and interpretability requirements.
Start with These Questions:
Before choosing a model, answer the following:
Do you have labeled data?
Yes → Supervised Learning
No → Unsupervised Learning
If supervised, are you predicting categories or continuous values?
Categories → Classification
Continuous values → Regression
How much labeled data do you have?
Less than 1,000 samples → Simple Models
More than 100,000 samples → Complex Models
Is interpretability required?
Yes → Linear/Tree Models
No → Any Model
Before diving into details, let’s first explore how to select a model based on the problem you want to solve.
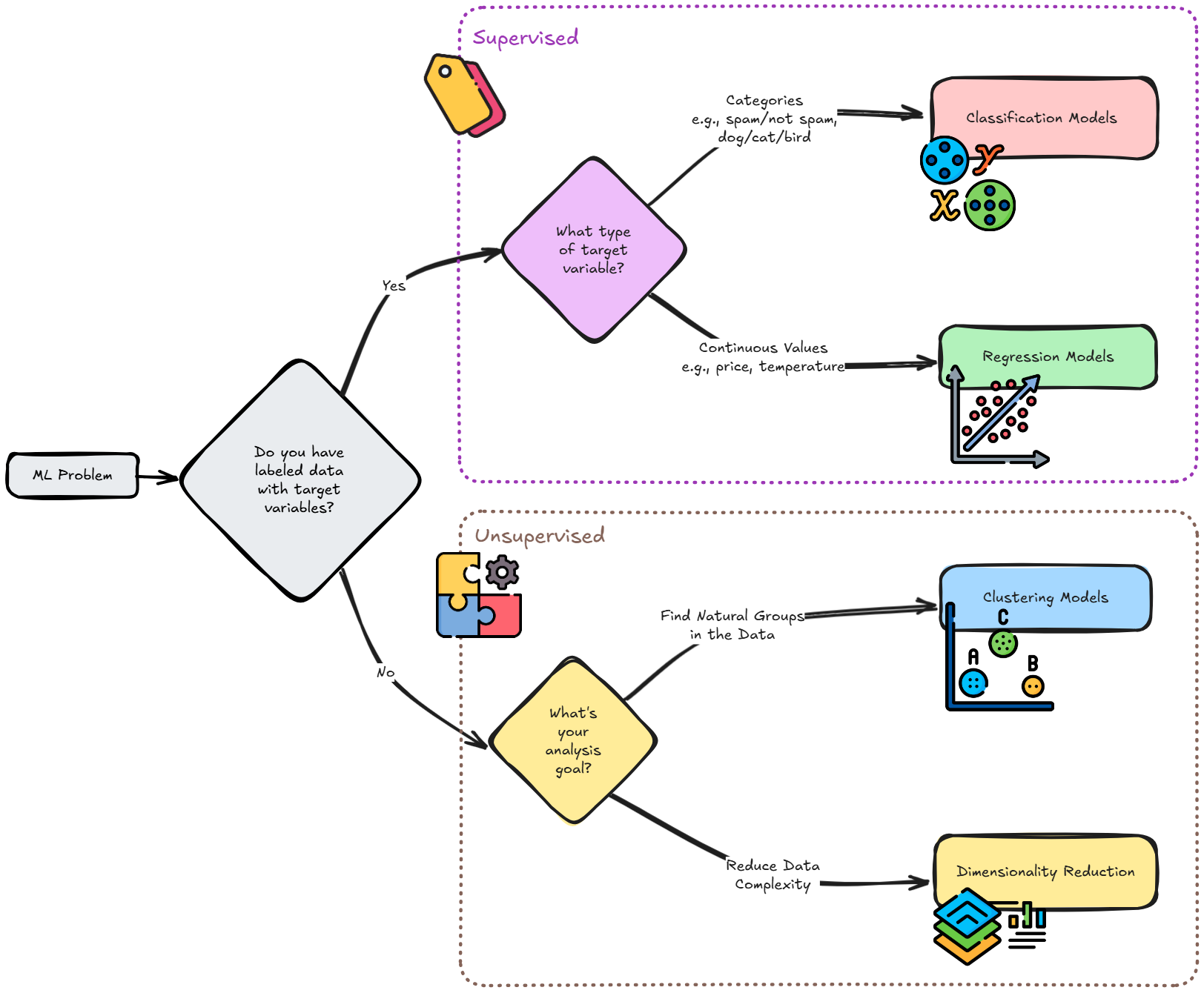
Below, you’ll find a structured breakdown of each type of problem, starting with a brief textual summary, followed by a more detailed flowchart.
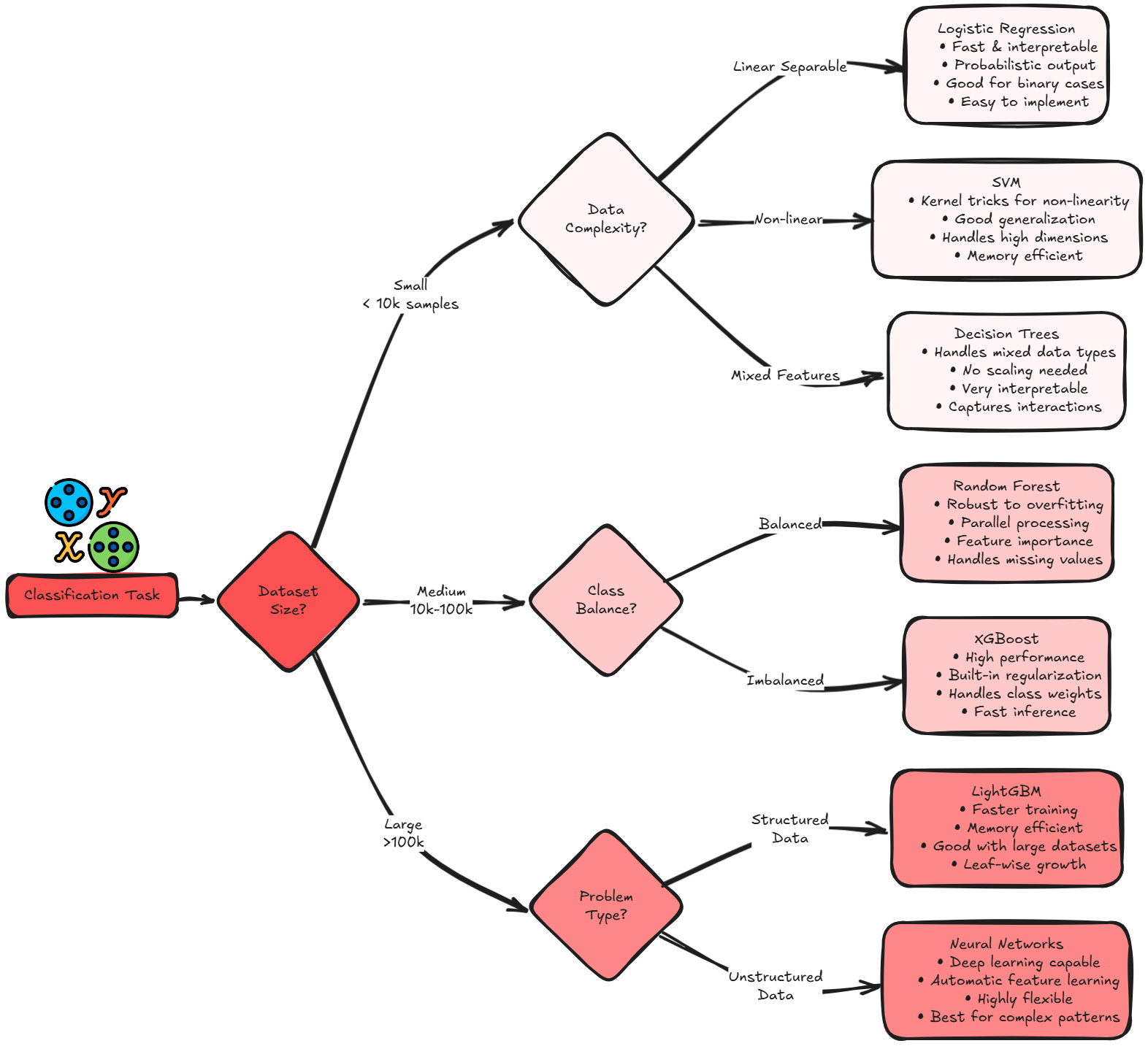
Classification Problems
Classification problems involve predicting discrete categories. The choice of model depends on factors like dataset size, feature complexity, and interpretability needs.
Binary classification with linear relationships → Logistic Regression
Complex relationships with moderate data → Random Forest
Large datasets with complex patterns → Neural Networks
Need interpretability → Decision Trees or Linear Models
High-dimensional sparse data → Linear SVM
Imbalanced classes → Ensemble Methods with class weighting
Regression Problems
Regression is used when predicting continuous values. The right model depends on feature relationships, dataset size, and the need for explainability.
Keep reading with a 7-day free trial
Subscribe to Machine Learning Pills to keep reading this post and get 7 days of free access to the full post archives.