


💊 Pill of the Week
Traditional chatbots start fresh with every conversation—they have no memory of who you are or what you've discussed before. But what if your chatbot could remember past interactions and learn about users over time?
In this article, we'll build exactly that: a Python-based conversational agent using LangGraph that can remember user information across sessions and automatically update that information as conversations progress. This isn't just about storing data—it's about creating an agent that naturally extracts and organizes information from normal conversation flow.
We'll cover this in three parts:
The concept: What the agent does and why it's useful
A complete example: How the agent processes a real conversation
The implementation: How the code actually works (💎a colab notebook is also shared at the end with all the code💎)

Part 1: Understanding the Agent
Core Functionality
This agent operates on a dual-track system during every conversation:
1. Retrieves existing information: When you ask "What city do you have on file for me?" the agent looks up your stored profile and gives you an accurate answer. It doesn't guess or hallucinate—it checks the actual data and reports back what it finds.
2. Captures new information: When you mention "I just moved to London and started painting," the agent automatically:
Recognizes these as new data points worth storing
Extracts them into structured format (location: "London", hobbies: ["painting"])
Saves them to your profile without interrupting the conversation
The magic is in the seamlessness. Users don't need to fill out forms or use special commands. They just talk naturally, and the agent handles both information retrieval and capture in the background. This creates a feedback loop where better memory leads to better conversations, which encourages users to share more, which improves the memory further.
Practical Applications
This architecture opens up several powerful use cases that go beyond simple Q&A:
Better customer service: Imagine calling support and the bot already knows you own the Pro version, had a billing issue last month, and prefer email communications. It can skip the entire triage process and immediately offer relevant solutions. For businesses, this means faster resolution times and happier customers.
Personal assistants that actually assist: A digital helper that remembers your daughter is allergic to peanuts, your anniversary is next week, and you're trying to learn Spanish can provide genuinely useful, proactive suggestions. It moves from being a reactive search tool to a proactive partner.
Automated CRM updates: Sales teams spend hours logging client interactions. An agent that can parse "The client mentioned they're expanding to Europe next quarter and need enterprise pricing" and automatically update the CRM saves time while ensuring nothing gets forgotten.
Educational companions: Tutoring bots that remember a student's weak areas, learning pace, and preferred explanation styles can provide truly personalized education that adapts over multiple sessions.
Healthcare intake: Medical assistants that can naturally collect patient history during conversation, remembering symptoms mentioned across multiple visits and flagging important changes to doctors.
The ReAct Pattern
The agent uses a "Reason and Act" (ReAct) pattern—a cognitive framework that mimics how humans solve problems. Unlike simple if-then chatbots, ReAct agents can plan multi-step solutions and adapt their approach based on intermediate results.

Here's what happens when you send a message like "What are my hobbies? By the way, I'm 28 now and I also enjoy coding":
Receive: The agent gets your raw message exactly as typed
Reason: The LLM (Large Language Model) breaks down the message:
Identifies a question: "What are my hobbies?"
Spots new information: age update (28) and new hobby (coding)
Plans the sequence: fetch profile first, then extract new details
Act: It executes the plan by calling tools:
Calls
get_user_profile(user_id=12345)to fetch current dataCalls
extract_personal_details(age=28, hobbies=["coding"])to structure the new info
Observe: The tools return their results:
Current profile shows existing hobbies: ["reading"]
Extraction confirms new data ready for storage
Respond: The agent:
Synthesizes a natural response: "According to your profile, your hobbies include reading. I'll also note that you enjoy coding and update your age to 28."
Triggers background profile update to merge new data
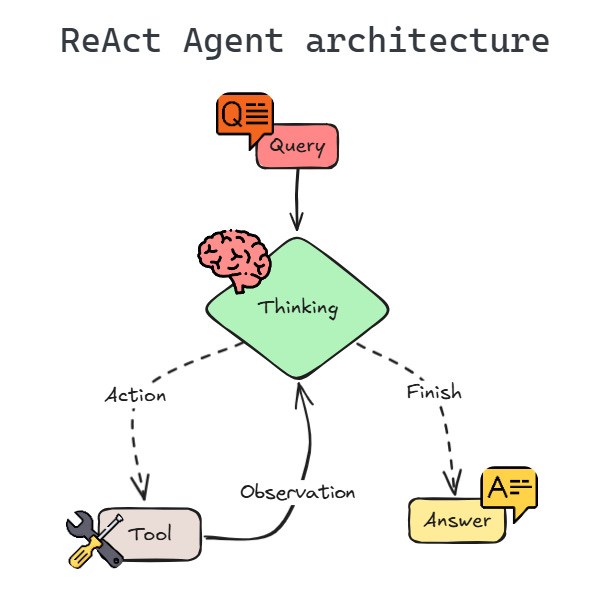
This pattern is powerful because the agent can adjust its approach mid-stream. If the profile lookup fails, it can acknowledge that and still save the new information. If the user's message is ambiguous, it can ask for clarification before proceeding.
📖 Book of the week
I just started reading The Definitive Guide to OpenSearch by Jon Handler, Soujanya Konka, and Prashant Agarwal — and it’s a must-have for anyone working with large datasets, search, or analytics.
What makes it stand out:
✅ Covers fundamentals and advanced optimizations
✅ Real-world case studies and hands-on demos
✅ Insights on scaling search and analytics systems
✅ Even explores Generative AI with OpenSearch
As data scientists and engineers, mastering search infrastructure is key to building scalable and intelligent systems — and this book brings best practices straight from AWS experts.
🔍 Highly recommended if you’re in AI/ML, data engineering, or system design.
👉 Check it out here: The Definitive Guide to OpenSearch
Part 2: A Complete Example
Let's walk through a real conversation to see what we aim to achieve.
Starting Scenario
Our user (ID: 12345) has this initial profile:
{
"name": "John Doe",
"age": 30,
"city": "New York",
"hobbies": ["reading"]
}The Conversation
User says: "Hi, what are my hobbies? Btw, I just moved to San Francisco, I'm 28 now, and I also enjoy coding."
Let's trace what happens:
Step 1: Message Processing
The agent receives the message and begins reasoning. It identifies:
A question that needs the current profile
Three pieces of new information to extract
Step 2: Tool Execution
The agent makes two tool calls:
First tool call - Getting current profile:
--- TOOL: Looking up profile for user_id: 12345 ---
Returns: {"name": "John Doe", "age": 30, "city": "New York", "hobbies": ["reading"]}
Second tool call - Extracting new details:
--- TOOL: Extracting details: {
'location': 'San Francisco',
'age': 28,
'hobbies': ['coding']
} ---
Step 3: Response Generation
The agent crafts a natural response:
"Based on your profile, your current hobbies include reading. I've noted that you also enjoy coding now. I've also updated your location to San Francisco and your age to 28. Is there anything specific you'd like to know about your updated profile?"
Step 4: Profile Update
Behind the scenes, the smart update function processes the new details:
# Before update:
{
"name": "John Doe",
"age": 30,
"city": "New York",
"hobbies": ["reading"]
}
# After smart merge:
{
"name": "John Doe",
"age": 28, # Updated scalar
"city": "New York", # Unchanged
"location": "San Francisco", # New field added
"hobbies": ["reading", "coding"] # List extended
}
Notice how:
The age was updated from 30 to 28
"location" was added as a new field (the agent used "location" instead of "city" for San Francisco)
The hobbies list was extended, not replaced
The name remained unchanged
Following Up
If the user continues the conversation:
User: "Actually, I also enjoy hiking and photography."
The agent would:
Extract
hobbies: ["hiking", "photography"]Merge them into the existing list
End up with
hobbies: ["reading", "coding", "hiking", "photography"]
This demonstrates the power of the append logic—information accumulates naturally over multiple interactions.
Part 3: Implementation Details
Now that we know what we want to achieve, let's examine how to do it, piece by piece.
1. State Management
The agent's working memory is deliberately minimal—just enough to maintain context without unnecessary complexity:
class MyState(AgentState):
user_id: intuser_id: The unique identifier that links this conversation to a specific user's datamessages: Inherited fromAgentState, this list tracks the entire conversation history including human inputs, AI responses, tool calls, and tool results
Why so simple? The state is transient—it only exists for the duration of a conversation. The permanent user data lives elsewhere (in a database or file), and the state just needs enough information to access it. This separation keeps the agent lightweight and allows the storage backend to be swapped out without changing the agent logic.
The messages list is particularly important because it provides the full audit trail. Every decision the agent makes, every tool it calls, and every result it receives gets logged here. This is invaluable for debugging and understanding the agent's reasoning process.
Keep reading with a 7-day free trial
Subscribe to Machine Learning Pills to keep reading this post and get 7 days of free access to the full post archives.