


💊 Pill of the week
Imagine you’re managing a complex research project. You need to analyze a company’s financial health, but that requires gathering quarterly reports, checking recent news, analyzing competitor data, and synthesizing market trends. No single person can efficiently do all of this at once—and asking them to do it sequentially would take forever.
This is where the Orchestrator-Worker pattern comes in. It’s a workflow pattern that transforms your AI from a solo performer into a coordinated team, with one “manager” LLM breaking down complex tasks and delegating specialized work to multiple “expert” workers.
Think of it like running a restaurant kitchen. The head chef (orchestrator) doesn’t cook every dish personally. Instead, they plan the menu, coordinate timing, and delegate: the grill station handles steaks, the pastry chef makes desserts, and the sous chef prepares sauces. Each specialist focuses on what they do best, and the head chef ensures everything comes together into a cohesive dining experience.
In the previous article we covered Parallelization, where independent predefined tasks run simultaneously:

The key difference? In Parallelization, all tasks are predetermined and run on the same input. In Orchestrator-Worker, the orchestrator dynamically decides what tasks to create, potentially with different inputs for each worker, and then synthesizes their diverse outputs into a final answer (which can also be run in parallel if wanted).
In this issue we will:
Define the “Orchestrator-Worker” pattern and explain its key benefits
Explore how to implement this pattern using LangChain
Build a step-by-step example that analyzes a company comprehensively using specialized workers 💎 With all the code + notebook! 💎
This is one out of several other workflow patterns, which we covered here:

Quick note before we start: I’ll be sharing the LangGraph version of this workflow in parallel later this week, available only to 💎paid subscribers.
Let’s begin with the Orchestrator-Worker pattern in LangChain!
Why is Orchestrator-Worker so Effective?
Task Decomposition: The orchestrator intelligently breaks down complex queries into manageable subtasks, each handled by the most appropriate specialist.
Specialization & Modularity: Each worker can use different models, prompts, tools, or knowledge bases optimized for their specific domain. You can easily add, remove, or replace workers without redesigning the entire system.
Scalability: As your requirements grow, you simply add new specialized workers rather than making one massive, unwieldy prompt.
Dynamic Adaptation: Unlike fixed patterns, the orchestrator can adjust its plan based on the query, skipping irrelevant subtasks or adding new ones as needed.
This pattern is perfect for scenarios where a complex question requires multiple types of expertise, and you need intelligent coordination rather than just running everything in a predetermined way in parallel.
Under the Hood
The Orchestrator-Worker pattern in LangChain involves three key components:
The Orchestrator: An LLM that analyzes the user’s request and creates a plan by breaking it into subtasks
The Workers: Specialized chains (potentially different LLMs, tools, or knowledge bases) that each handle one type of subtask
The Synthesizer: An LLM that takes all worker outputs and integrates them into a coherent final answer
The flow looks like this:
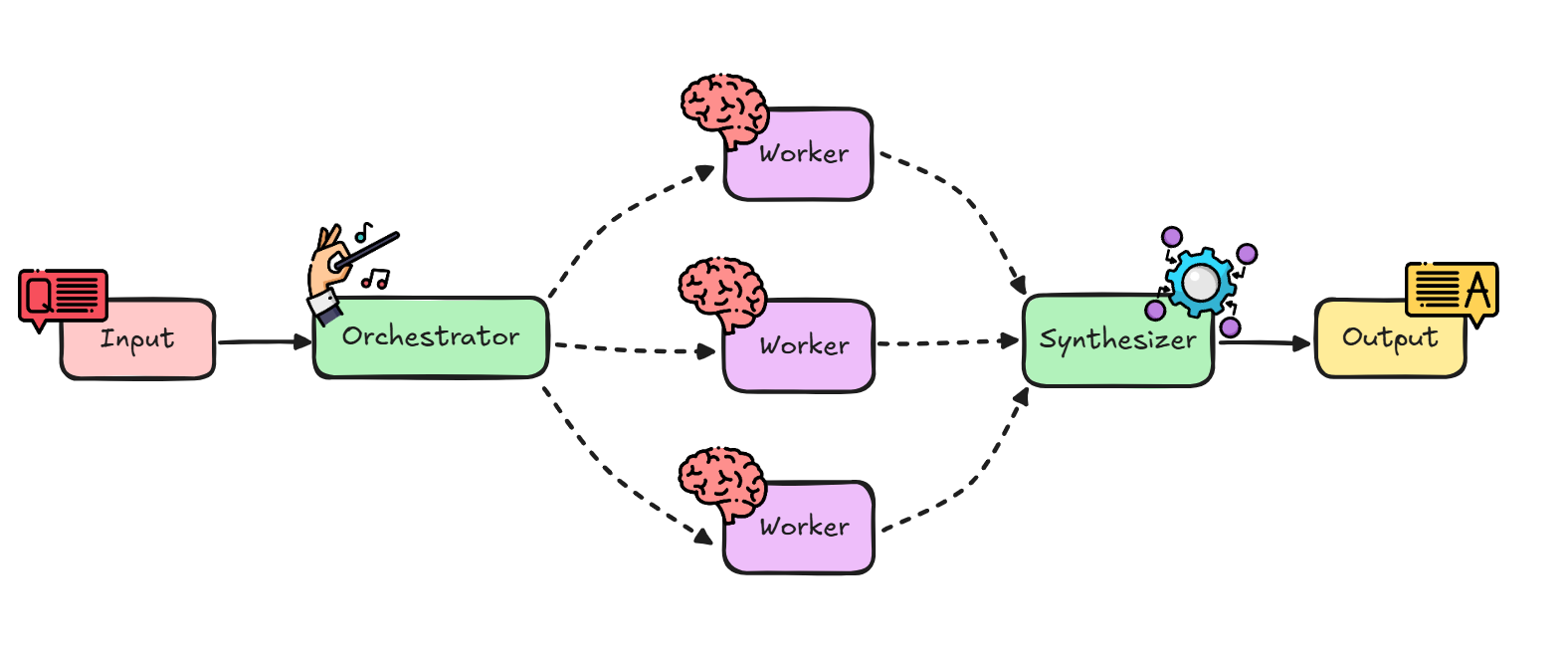
Let’s see this in action.
🛠️ DIY: Product Launch Analysis
Imagine you’re building an internal analysis tool for your company. When preparing for a product launch review, you need to provide a comprehensive analysis covering multiple dimensions: technical readiness, market positioning, and risk assessment—all from internal documentation and simulated data.
The Challenge
We’ll take a product name and use an orchestrator to:
Determine which aspects of the product need analysis
Delegate each aspect to a specialized worker:
Technical Readiness Worker: Analyzes features and development status
Market Position Worker: Evaluates competitive positioning and target audience
Risk Assessment Worker: Identifies potential challenges and mitigation strategies
Synthesize all findings into a comprehensive launch readiness report
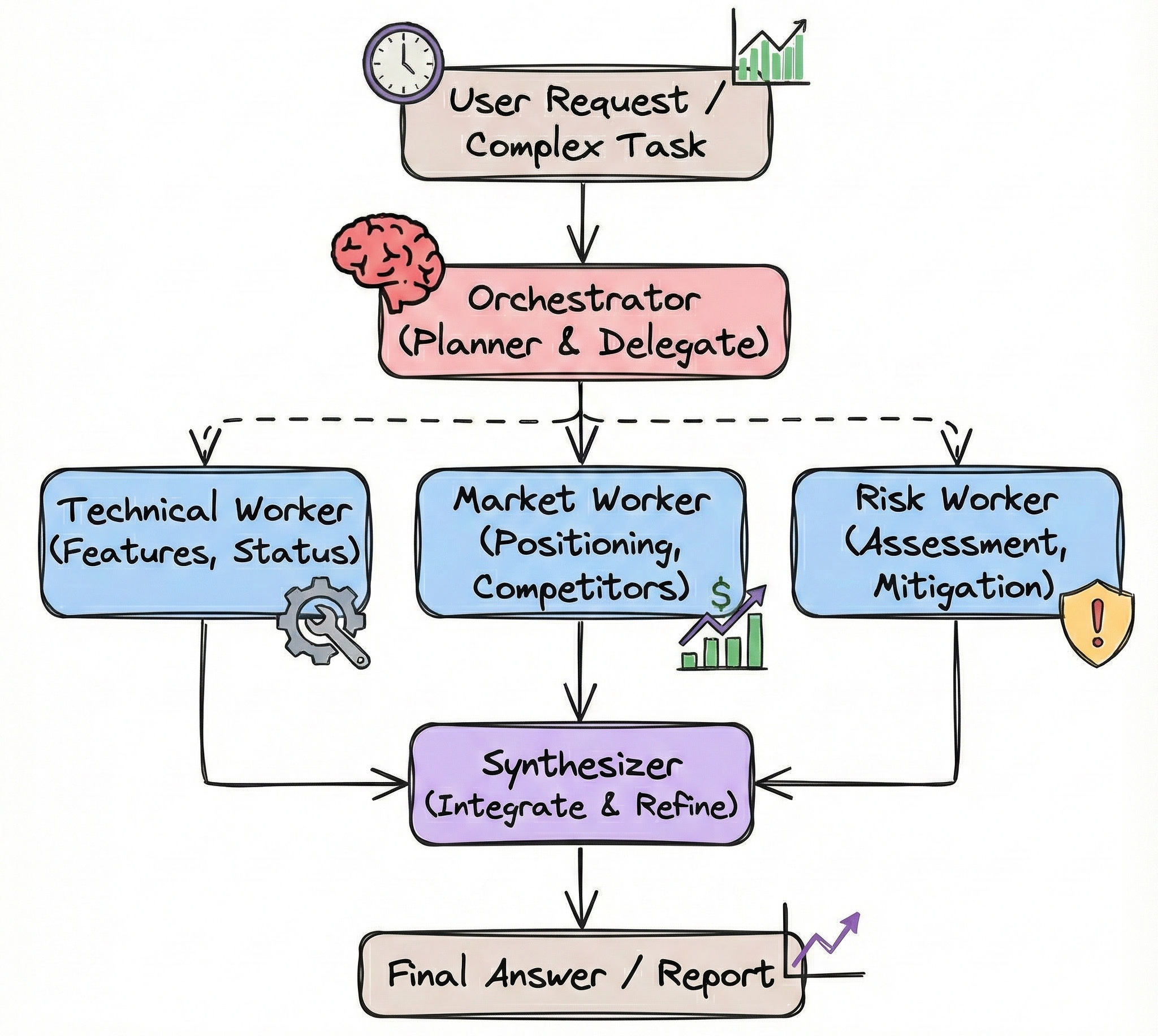
As an example, we’ll analyze: “SmartHome Hub Pro”
Let’s begin!
Setting the Stage
First, we need our LangChain tools and our LLM. We’ll also import Pydantic to define structured outputs.
# Install necessary libraries if you haven’t already
# !pip install langchain-openai langchain pydantic
import os
from typing import List, Dict
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser, JsonOutputParser
from langchain_core.pydantic_v1 import BaseModel, Field
# Set up your OpenAI API key
# os.environ[”OPENAI_API_KEY”] = “your_api_key”
# Initialize our LLMs
orchestrator_llm = ChatOpenAI(model=”gpt-4o”, temperature=0)
worker_llm = ChatOpenAI(model=”gpt-4o-mini”, temperature=0.3)
synthesizer_llm = ChatOpenAI(model=”gpt-4o”, temperature=0.2)orchestrator_llm: Uses the more capable model for planning (temperature=0 for consistency)worker_llm: Uses a faster, cheaper model for specialized taskssynthesizer_llm: Uses the capable model again for final integration
Step 1: Building the Orchestrator
The orchestrator’s job is to analyze the query and create a structured plan of subtasks.
# Define the plan structure
class SubTask(BaseModel):
task_id: str = Field(description=”Unique identifier for the subtask”)
worker_type: str = Field(description=”Type of worker needed: ‘technical’, ‘market’, or ‘risk’”)
instructions: str = Field(description=”Specific instructions for this subtask”)
class Plan(BaseModel):
product: str = Field(description=”The product being analyzed”)
subtasks: List[SubTask] = Field(description=”List of subtasks to execute”)
# Set up the orchestrator parser
orchestrator_parser = JsonOutputParser(pydantic_object=Plan)
# Create the orchestrator prompt
orchestrator_prompt = ChatPromptTemplate.from_messages([
(”system”, “”“You are an expert product launch coordinator. Your job is to analyze a product launch request and break it down into specific subtasks for specialized workers.
Available workers:
- ‘technical’: Analyzes technical readiness, features, and development status
- ‘market’: Evaluates market positioning, target audience, and competitive landscape
- ‘risk’: Identifies potential risks and mitigation strategies
For the given product, create a comprehensive plan that covers all relevant aspects for launch readiness. Each subtask should have clear, specific instructions.”“”),
(”user”, “Product to analyze: {product}\n\n{format_instructions}”)
]).partial(format_instructions=orchestrator_parser.get_format_instructions())
# Define the orchestrator chain
orchestrator_chain = orchestrator_prompt | orchestrator_llm | orchestrator_parser
We define a structured
Planwith multipleSubTaskobjectsThe orchestrator receives the product name and creates a JSON plan
Each subtask specifies which worker type to use and what that worker should do. In this case we defined three different workers, which we will implement in the next step:
the technical specialist
the market specialist
the risk specialist
📖 Book of the Week
If you are building enterprise-grade LLM systems or are responsible for bringing GenAI into complex organisational environments, this is a standout strategic and practical guide.
“LLMs in Enterprise: Design strategies, patterns, and best practices for large language model development” by Ahmed Menshawy and Mahmoud Fahmy

💡 A comprehensive, end-to-end playbook for designing, optimising, deploying, and governing large language model applications at enterprise scale. You will move from foundational concepts through to advanced design patterns, fine-tuning approaches, deployment architectures, and real operational concerns such as evaluation, monitoring, compliance, and cost optimisation.
What sets it apart
It brings a deeply structured, pattern-driven perspective to enterprise LLM development, going far beyond simple demos or hobby-level guidance. You get clear strategies for real-world challenges: scaling across business units, improving reliability, integrating RAG, ensuring fairness and transparency, and managing production LLM systems responsibly.
Each chapter bridges theory with pragmatic guidance, giving teams a common language for building robust and future-proof GenAI applications.
You will learn to:
✅ Apply proven design patterns to integrate LLMs into enterprise systems
✅ Overcome challenges in scaling, deploying, and optimising LLM applications
✅ Use fine-tuning techniques, contextual customisation, and RAG to boost performance
✅ Build data strategies that genuinely improve LLM quality and reliability
✅ Implement advanced inferencing engines and performance optimisation patterns
✅ Evaluate LLM applications with enterprise-ready metrics and frameworks
✅ Monitor production LLMs and ensure security, privacy, and compliance
✅ Understand responsible AI practices, including transparency and robustness
✅ Track emerging trends, multimodality, and the next wave of GenAI capabilities
If you are serious about deploying LLMs across an organisation and want proven patterns that reduce risk and accelerate delivery, this is the resource that turns experimentation into scalable enterprise AI.
Step 2: Building the Specialized Workers
Each worker is a specialized chain optimized for its domain, with access to relevant internal data (PRODUCT_DATABASE).
Worker 1: Technical Readiness Analyst
technical_prompt = ChatPromptTemplate.from_template(
“”“You are a technical readiness expert. Analyze the following product based on these instructions:
Product: {product}
Instructions: {instructions}
Product Data:
Features: {features}
Development Status: {development_status}
Provide a concise but thorough technical readiness analysis. Assess completeness, quality indicators, and readiness for launch.”“”
)
def technical_worker_invoke(inputs):
product = inputs[’product’]
product_data = PRODUCT_DATABASE.get(product, {})
return (technical_prompt | worker_llm | StrOutputParser()).invoke({
“product”: product,
“instructions”: inputs[’instructions’],
“features”: product_data.get(’features’, []),
“development_status”: product_data.get(’development_status’, {})
})Worker 2: Market Position Analyst
Keep reading with a 7-day free trial
Subscribe to Machine Learning Pills to keep reading this post and get 7 days of free access to the full post archives.