

Issue #105 - Randomisation & Stratification in A/B Testing

💊 Pill of the Week
In the first part of this series, we explored the fundamentals of A/B testing: how to form a solid hypothesis, design a robust experiment, and analyse results with statistical confidence.

Now it’s time to tackle one of the most overlooked—but most critical—steps in the process: how to assign users into groups.
A fair comparison depends on fair groups. If your assignment isn’t carefully managed, your test risks being biased before it even begins.
We’ll start by walking through the key techniques for assigning users into groups, and then share a 💎ready-to-use notebook💎 that brings everything together—so you can apply these methods directly in your own experiments.
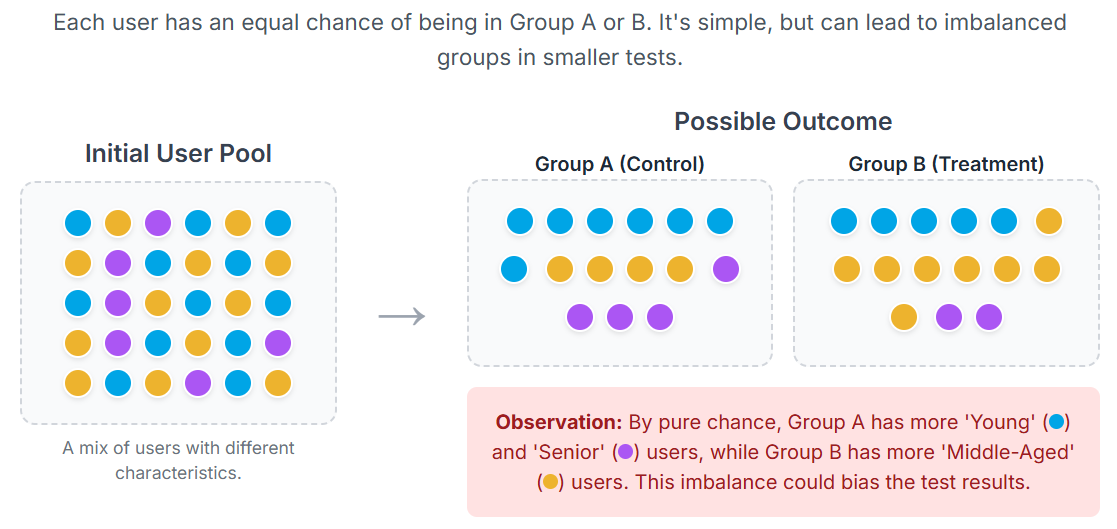
Why Randomisation Matters?
Randomisation ensures that each user has an equal chance of being assigned to either the control group (A) or the treatment group (B). This prevents pre-existing differences in your user base from skewing the results.
Think of it as shuffling a deck of cards before dealing. If you don’t shuffle, one player might get all the aces and another none—making the game unfair.
In A/B testing, randomisation is your shuffle.
A quick Python example:
import random
users = ["user1", "user2", "user3", "user4", "user5"]
assignments = {u: random.choice(["A", "B"]) for u in users}
print(assignments)
# {'user1': 'A', 'user2': 'A', 'user3': 'A', 'user4': 'A', 'user5': 'B'}This snippet randomly assigns each user to either group A or B. Simple, quick, and effective when you have a large population size where natural balancing is expected.
The Limitations of Pure Randomisation
While pure randomisation works well for large samples, it can fall short in smaller or more specialised experiments. For example, what if your experiment only has 200 participants? By chance, one group could end up with a higher proportion of young, active users, while the other gets older, less active ones.
The result? An unfair comparison. If Group B performs better, is it really because of your new product feature—or just because they happened to start out fitter and healthier?
This is where stratification comes in.
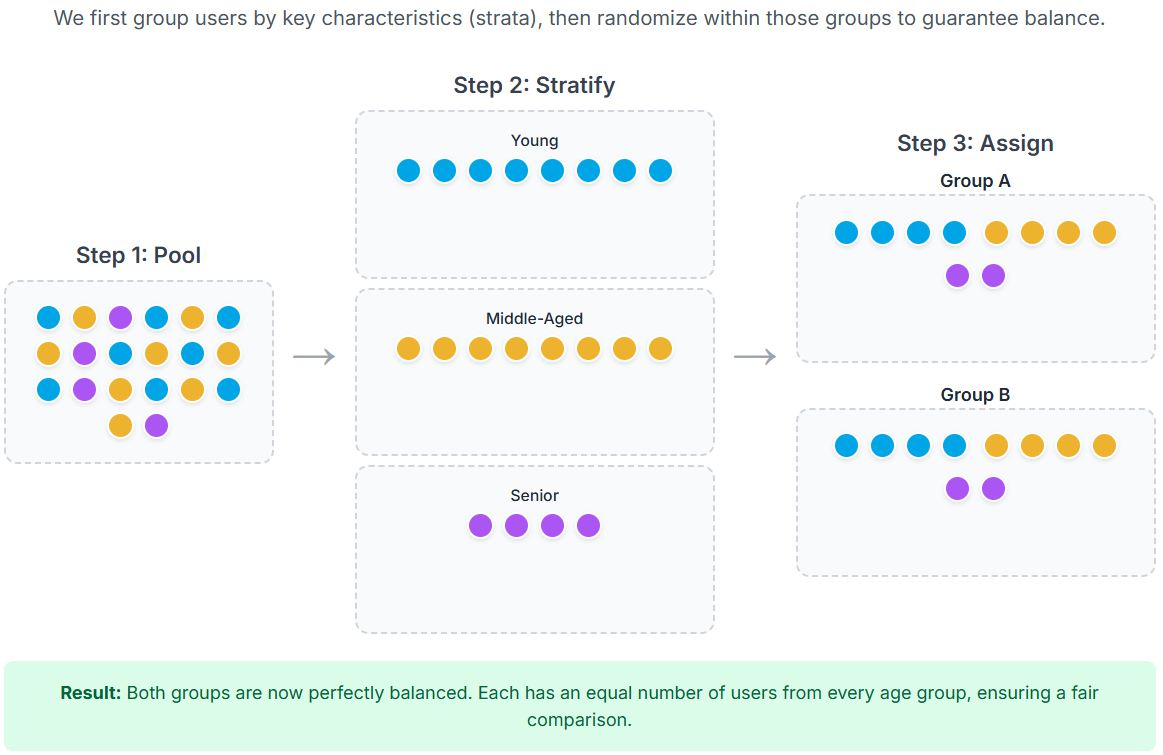
Stratification: Fairness by Design
Stratification ensures balance by design, not just by chance. Instead of relying on randomness alone, you deliberately group users into “strata” based on key characteristics, then randomise within each stratum.
This guarantees that both the control and treatment groups are comparable across the factors that matter most.
A Practical Example: Nutrition Experiment
Imagine you are testing a new nutrition programme and want to split users into two balanced groups. Key characteristics you care about include:
Age
Height
Daily calorie intake
Weight
Number of daily steps
Workout frequency (days per week)
If you used pure randomisation, you might accidentally create uneven groups: one with mostly young, active participants and the other with older, less active ones. Stratification avoids this by balancing the groups on these variables before the test starts.
Implementing Stratification with Clustering
One way to achieve this is through clustering. You can use machine learning to group similar users together and then assign them to different test groups within each cluster.
Here’s a simplified Python example:
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
import numpy as np
# Step 1: Standardise so no feature dominates
scaler = StandardScaler()
scaled = scaler.fit_transform(data)
# Step 2: Cluster users into groups with similar profiles
kmeans = KMeans(n_clusters=2, random_state=42, n_init=10)
data["cluster"] = kmeans.fit_predict(scaled)
# Step 3: Randomly assign within each cluster
data["group"] = data.groupby("cluster")["cluster"].transform(
lambda x: np.random.choice(["A", "B"], size=len(x))
)
print(data[["age", "weight", "steps", "group"]])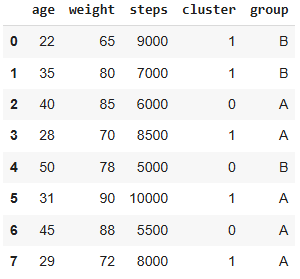
We can average each group to see how well we did:
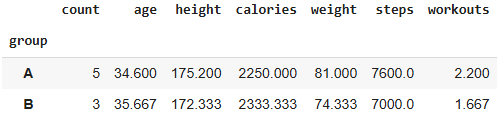
Explanation:
Standardisation: Makes sure variables like “calories” and “steps” are on the same scale.
Clustering: Groups users with similar health and activity profiles.
Randomisation within clusters: Ensures both A and B contain comparable mixes of user types.
When to Use Which Method
Pure randomisation: Best for large samples, quick tests, and when no single variable is expected to dominate outcomes.
Stratification: Best for smaller experiments or when known factors (like age, income, or activity level) could bias results if left unchecked.
In short:
Randomisation = fairness by chance.
Stratification = fairness by design.
Final Thoughts
The quality of an A/B test doesn’t just come from clever hypotheses or powerful statistical analysis—it starts at the very moment you decide who goes into Group A and who goes into Group B.
Randomisation ensures fairness by giving everyone an equal chance. Stratification goes a step further, deliberately balancing important characteristics to avoid hidden biases.
By applying these methods thoughtfully, you build more trustworthy experiments, generate clearer insights, and ultimately make better decisions.
📖 Book of the week
Building AI Agents with LLMs, RAG, and Knowledge Graphs by Salvatore Raieli and Gabriele Iuculano

This is a practical, end-to-end guide for anyone who wants to move from clever prompts to working agentic systems that reason, retrieve and act.
Raieli and Iuculano keep the focus on delivery. You get a clear path from concept to production, with Python examples throughout, showing how to wire LLMs to external data via RAG, layer in knowledge graphs for context, and orchestrate agents that plan, use tools and complete multi-step tasks. The coverage of monitoring, reducing hallucinations, and handling long-running memory is especially useful if you aim to ship reliable features rather than demos.
Why it stands out
Treats RAG and knowledge graphs as first-class parts of the system, not afterthoughts
Balances architecture with hands-on code using familiar libraries like LangChain
Looks beyond prototypes to deployment, observability and iteration
Best for
Data scientists, ML engineers and technical product folks with basic Python and GenAI knowledge who want a concrete playbook for building autonomous, industry-ready agents.
Bottom line
A solid, practical reference that will help you design agents grounded in real data and capable of completing meaningful tasks. If agentic systems are on your roadmap this year, this book is worth your time.
⚡️Power-Up Corner
If you want to go further than randomisation and stratification, here are two additional techniques we can use to create test groups that are both fair and insightful. A full notebook is enclosed at the end with all the techniques mentioned in the article! 💎Only for Paid Subscribers.💎
Matching Pairs
Matching Pairs creates the most balanced groups possible. The idea is to find two users who are almost identical based on key features, pair them up, and then randomly assign one to Group A and the other to Group B. This process is repeated until all users are assigned.
