


💊 Pill of the week
Retrieval-Augmented Generation (RAG) models have revolutionized the way we handle complex information retrieval tasks by combining the power of retrieval systems with the generative capabilities of large language models. These models have shown remarkable improvements in various natural language processing tasks, including question answering, fact verification, and open-domain dialogue systems.
However, to fully leverage the potential of RAG models, it is essential to employ advanced retrieval strategies. This article will cover several techniques designed to enhance the retrieval effectiveness in RAG models.
Advanced Retrieval in RAG
Before diving into specific techniques, it's crucial to understand why advanced retrieval strategies are so important in the context of RAG models:
Improved Accuracy: By retrieving more relevant information, RAG models can generate more accurate and contextually appropriate responses.
Enhanced Comprehensiveness: Advanced retrieval techniques allow RAG models to access a broader range of relevant information, leading to more comprehensive outputs.
Reduced Hallucination: Better retrieval can mitigate the problem of "hallucination" in language models by grounding responses in factual, retrieved information.
Handling Complex Queries: Advanced strategies enable RAG models to effectively deal with multi-faceted or ambiguous queries that simple retrieval methods might struggle with.
Adaptability: These techniques allow RAG models to adapt to different types of queries and domains more effectively.
Now, let's explore the three advanced Query Translation techniques in more detail.
Query Translation Techniques
Query translation is a technique used in advanced information retrieval systems to improve the effectiveness of the search process. It involves transforming or reformulating the original user query into one or more alternative forms that are more likely to match relevant documents or information in the knowledge base. This process can include various strategies such as rephrasing the query, expanding it with synonyms or related terms, breaking it down into sub-queries, or even generating hypothetical contexts based on the query. The goal of query translation is to bridge the gap between the user's natural language input and the way information is stored or indexed in the system, thereby enhancing the retrieval of pertinent information and ultimately improving the quality of the generated responses.
There are five main types:
Multi Query
RAG Fusion
Query Decomposition
Step Back
Hypothetical Document Embeddings (HyDE)
In this article we will introduce the first two:
📚 Multi Query
Multi Query is a technique that involves generating multiple variations of the original query to improve the chances of retrieving relevant information. This approach leverages the power of language models to rephrase and expand upon the initial query, capturing different aspects or interpretations of the user's intent.
When to Use
Use Multi Query when dealing with complex or ambiguous queries, or when initial retrieval results are unsatisfactory. This technique is particularly useful in scenarios where the original query might not fully capture the user's intent or when the desired information could be expressed in various ways.
Example
For the original query "What are the effects of climate change on agriculture?", Multi Query might generate variations such as:
"How does global warming impact crop yields?"
"What are the challenges farmers face due to changing weather patterns?"
"Discuss the relationship between rising temperatures and agricultural productivity."

Implementation Details
To implement Multi Query:
Develop a query generation model:
Fine-tune a language model on a dataset of query pairs or expansions.
Train the model to generate diverse yet relevant query variations.
Create a pipeline that: a. Takes the original query as input. b. Generates multiple query variations (typically 3-5). c. Performs retrieval for each query variation. d. Aggregates and ranks the retrieved results.
Implement diversity measures to ensure generated queries cover different aspects of the original query.
Develop a ranking system to prioritize retrieved documents based on their relevance across multiple queries.
Advantages
Improves recall by capturing different aspects of the user's intent
Helps overcome limitations of the original query formulation
Increases the chances of retrieving relevant information, especially for complex topics
Challenges
Balancing query diversity with relevance
Computational overhead of processing multiple queries
Effectively aggregating and ranking results from multiple queries
💥 RAG Fusion
RAG Fusion is an advanced technique that combines query rewriting with multiple retrievals and result fusion. This approach involves rewriting the original query from multiple perspectives, performing retrieval for each rewritten query, and then applying reciprocal rank fusion to consolidate the results. By leveraging diverse query formulations, RAG Fusion aims to improve the overall quality and relevance of retrieved information.
When to Use
Apply RAG Fusion when dealing with complex or ambiguous queries that might benefit from multiple interpretations. This technique is particularly useful in scenarios where a single query formulation might miss important aspects of the user's intent, or when working across diverse domains where information can be expressed in various ways.
Example
For a query about "The impact of renewable energy on climate change", RAG Fusion might:
Generate rewritten queries such as:
"How do solar and wind power contribute to reducing greenhouse gas emissions?"
"What are the environmental benefits of transitioning to renewable energy sources?"
"Discuss the role of renewable energy in mitigating global warming."
Perform retrieval for each rewritten query.
Apply reciprocal rank fusion to consolidate the retrieval results.

Implementation Details
To implement RAG Fusion:
Develop a query rewriting model:
Fine-tune a language model to generate diverse yet relevant query variations.
Ensure the model captures different aspects or perspectives of the original query.
Create a fusion pipeline:
Take the original query as input.
Generate multiple rewritten queries (typically 3-5).
Perform retrieval for each rewritten query using a chosen retrieval method (e.g., dense retrieval, BM25).
Apply reciprocal rank fusion to consolidate the results:
For each document, calculate its fused score based on its ranks in different result lists.
The reciprocal rank fusion formula:

for each rank rᵢ of document d, where k is a constant (often set to 60).
Produce a final ranked list of documents based on the fused scores.
Optimize the fusion process:
Experiment with different numbers of rewritten queries.
Fine-tune the reciprocal rank fusion parameters (e.g., the k constant).
Consider incorporating relevance feedback to improve query rewriting and fusion.
Implement diversity measures in both query rewriting and result fusion to ensure broad coverage of relevant information.
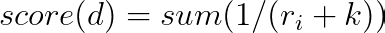
Advantages
Captures different aspects of the user's intent through query rewriting
Improves retrieval robustness by considering multiple query formulations
Enhances both precision and recall of retrieved information
Mitigates the impact of suboptimal query formulations
Challenges
Balancing query diversity with relevance in the rewriting process
Computational overhead of processing multiple queries and fusing results
Ensuring that rewritten queries maintain the core intent of the original query
Tuning the reciprocal rank fusion process for optimal performance across different types of queries and domains
Implementation Details
To implement RAG Fusion:
Select multiple retrieval methods:
Choose complementary retrieval approaches (e.g., dense and sparse retrievals).
Consider domain-specific retrieval methods if applicable.
Develop a fusion pipeline: a. Process the query through each selected retrieval method. b. Normalize scores across different retrieval methods. c. Implement a fusion algorithm (e.g., reciprocal rank fusion, CombSUM, or learned rank fusion). d. Aggregate and re-rank the combined results.
Implement a learning-to-rank model to optimize the fusion process:
Train on relevance judgments or user feedback.
Fine-tune the model to balance the influence of different retrieval methods.
Incorporate diversity measures to ensure a broad coverage of relevant information.
Advantages
Leverages strengths of multiple retrieval methods
Improves both precision and recall of retrieved information
Enhances robustness across different query types and domains
Challenges
Increased computational complexity
Balancing the influence of different retrieval methods
Ensuring coherence in the final set of retrieved documents
How to integrate it in RAG Models?
To effectively incorporate these advanced retrieval strategies into RAG models:
Preprocessing: Implement robust query analysis to determine which strategy (or combination of strategies) is most appropriate for each input.
Strategy Selection: Develop a decision-making framework that selects the most suitable retrieval strategy based on query characteristics, domain context, and available information.
Parallel Processing: Where applicable, apply multiple strategies in parallel and aggregate the results to improve comprehensiveness.
Iterative Refinement: Implement feedback loops that allow for iterative refinement of retrieval strategies based on initial results.
Post-processing: Develop methods to recompose and synthesize information retrieved through different strategies into coherent and contextually appropriate responses.
Evaluation Metrics: Establish comprehensive evaluation metrics that assess not only the relevance of retrieved information but also its diversity, novelty, and alignment with user intent.
Advanced retrieval strategies, particularly in the domain of Query Translation, are crucial for maximizing the potential of RAG models. Techniques such as Query Decomposition, Step Back, and Hypothetical Document Embeddings offer powerful ways to enhance the retrieval process, leading to more accurate, comprehensive, and contextually appropriate responses.
As the field of natural language processing continues to evolve, these strategies will play an increasingly important role in bridging the gap between user queries and available information. By effectively implementing and combining these techniques, RAG models can achieve new levels of performance in a wide range of applications, from question answering systems to intelligent research assistants.
🎓Learn Real-World Machine Learning!*
Do you want to learn Real-World Machine Learning?
Data Science doesn’t finish with the model training… There is much more!

Here you will learn how to deploy and maintain your models, so they can be used in a Real-World environment:
Elevate your ML skills with "Real-World ML Tutorial & Community"! 🚀
Business to ML: Turn real business challenges into ML solutions.
Data Mastery: Craft perfect ML-ready data with Python.
Train Like a Pro: Boost your models for peak performance.
Deploy with Confidence: Master MLOps for real-world impact.
🎁 Special Offer: Use "MASSIVE50" for 50% off. Only this time!
*Sponsored
🤖 Tech Round-Up
No time to check the news this week?
This week's TechRoundUp comes full of AI news. From Global IT Outage Chaos to the latest AI fund. Let's dive into the latest Tech highlights you probably shouldn’t this week 💥
A major IT outage caused by CrowdStrike's update to its antivirus software has hit Microsoft Windows users worldwide. Airports, banks, and healthcare services have been affected, causing massive disruptions. 🌍
2️⃣ Apple Intelligence is Coming!
Apple is launching "Apple Intelligence" soon! Expect AI to be integrated into iOS and macOS.
This could change how we use Apple devices.
3️⃣ AI Training with YouTube Videos
Over 100k YouTube videos have been scraped to train AI models for Apple and Nvidia.
Privacy concerns are rising! How do you feel about your data being used this way?
4️⃣ Samsung’s Latest Acquisition
🧠 Samsung is set to acquire Oxford Semantic Technologies, a UK-based startup known for its advanced knowledge graph tech.
This will boost Samsung’s AI capabilities significantly!
💰 Menlo Ventures and Anthropic are teaming up on a $100M AI fund.
This partnership aims to support startups working on next-gen AI technologies.
Keep reading with a 7-day free trial
Subscribe to Machine Learning Pills to keep reading this post and get 7 days of free access to the full post archives.