

Issue #109 - Intent Classification for AI Agents
A Smarter Way to Route User Requests

💊 Pill of the week
Imagine you’re building an AI nutrition assistant. Your agent can search nutritional databases, find recipes, track calories, schedule meal plans, and provide health advice. The straightforward approach? Connect all these tools to a single reasoning node and let the AI figure out which tool to use for each request.
This seems logical at first. After all, modern language models are incredibly capable at understanding context and making decisions. However, this “all-in-one” approach quickly becomes problematic as your application grows.
Let’s first introduce the concept and then proceed to implement it.
💎Also we’ll share the full code!💎
What is Intent Classification?
Intent classification is the process of analyzing a user’s input and determining what they’re actually trying to accomplish before taking any action. Think of it as a smart receptionist at a hospital who quickly understands whether you need the emergency room, a scheduled appointment, or just directions to the pharmacy.
In the context of AI agents, intent classification acts as a routing layer that sits between the user’s request and your various tools or capabilities. Instead of forcing your AI to consider all possible actions for every single request, you first classify what the user wants, then route them directly to the appropriate specialized handler.
Why Intent Classification Matters?
These are the main reasons:
Reducing Token Costs and API Expenses
Avoiding Context Window Limitations
Faster Response Times
Improved Accuracy and Reliability
Better Architecture and Maintainability
Enhanced User Experience Through Specialized Handling
Let’s now cover them in depth:
1. Reducing Token Costs and API Expenses
This is perhaps the most immediate practical benefit. When you connect multiple tools to a single reasoning node, every tool’s description, parameters, and usage instructions must be included in the context for every request.

Let’s say you have 10 tools, each with a 200-token description. That’s 2,000 tokens of overhead on every single API call, even when 9 of those tools are completely irrelevant to the user’s request. With intent classification, you only send the relevant tool descriptions after routing, potentially reducing your token usage by 80-90%.
At scale, this isn’t just about a few cents here and there. If your application processes thousands of requests daily, intent classification can save thousands of dollars monthly in API costs.
2. Avoiding Context Window Limitations
Modern LLMs have impressive context windows, but they’re not infinite. As you add more tools, features, and capabilities to your AI agent, you’re competing for limited context space. Intent classification helps you stay within these limits by ensuring only relevant information is included in each request.
3. Faster Response Times
When an LLM has to process fewer tokens, it responds faster. But there’s another performance benefit: the cognitive load on the model is significantly reduced. Instead of asking the AI to evaluate 10 different possible actions, understand their nuances, and make a complex decision, you’re first making a simpler classification decision, then executing a targeted action.
This is similar to how human decision-making works. We don’t evaluate every possible action we could take at every moment. We quickly categorize the situation (”I’m hungry,” “I need to learn something,” “I should exercise”) and then focus on the relevant options within that category.
4. Improved Accuracy and Reliability
When your AI has to juggle too many options simultaneously, it’s more likely to make mistakes. Tool descriptions might be similar, parameters might overlap, or the model might simply get confused by the complexity.
By routing requests through intent classification first, you’re breaking down a complex decision into two simpler ones:
What type of request is this? (classification)
How do I handle this specific type of request? (execution)
Each step is simpler and more reliable than trying to do everything at once.
5. Better Architecture and Maintainability
From a software engineering perspective, intent classification creates clean separation of concerns. Each intent can have its own specialized logic, error handling, and data processing pipeline. When you need to update how recipe searches work, you don’t risk breaking the nutritional database functionality.
This modularity makes your codebase easier to understand, test, and maintain. New developers can quickly grasp that “recipe searches go through this path” without having to understand the entire system.
6. Enhanced User Experience Through Specialized Handling
Different types of requests might need different handling approaches. A recipe search might benefit from image results and cooking instructions, while nutritional information needs tables and charts. Health symptom questions might require disclaimers and escalation to human experts.
Intent classification allows you to tailor the experience for each category of request, rather than forcing a one-size-fits-all approach.
The Traditional Approach vs. Intent Classification
To truly understand the value of intent classification, let’s compare it directly to the traditional “all-in-one” approach. The differences become strikingly clear when we look at what happens during a single user request.
Traditional Approach (All Tools Connected)
In the traditional architecture, every single request forces the AI to consider every possible action it could take. Imagine a user asks: “How much protein should I eat per day?”
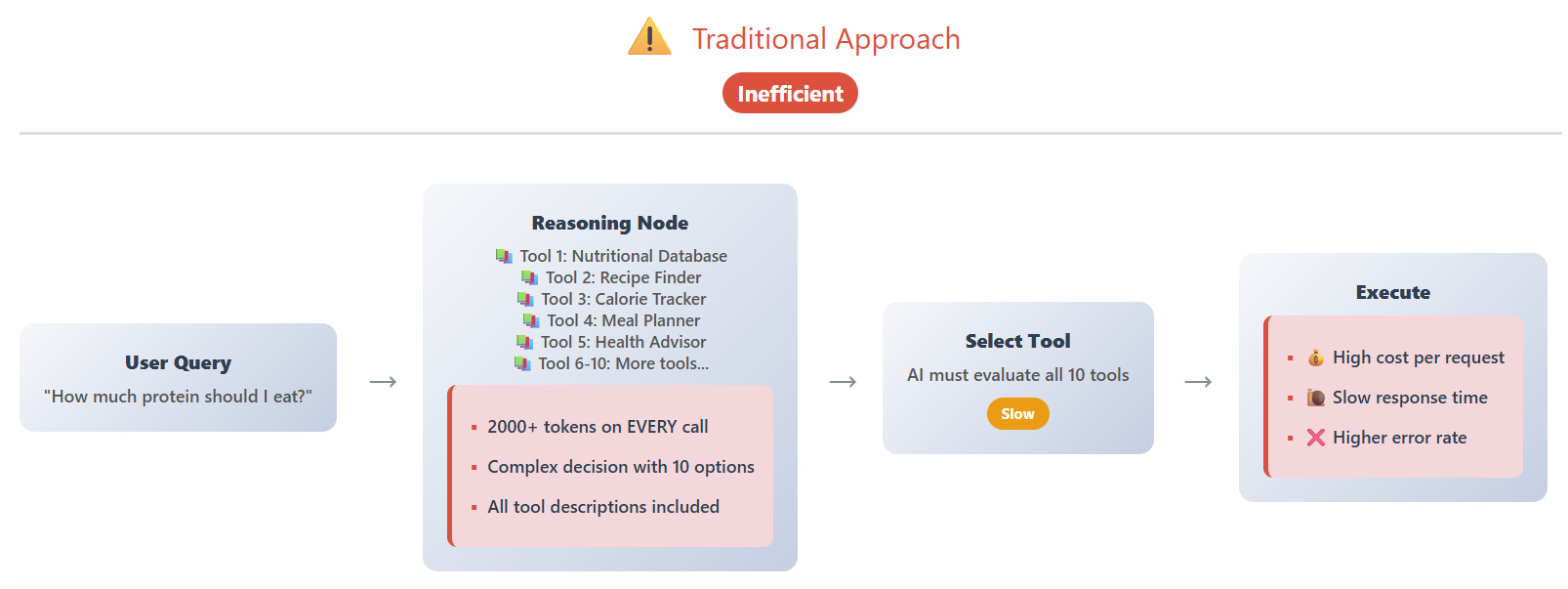
Here’s what happens behind the scenes: The reasoning node must load descriptions for all 10 tools—the nutritional database, recipe finder, calorie tracker, meal planner, health advisor, and five others. Each tool description includes its purpose, parameters, usage examples, and constraints. All of this information gets sent to the LLM on every single request, regardless of relevance.
The AI then performs a complex evaluation: “Should I use the nutrition database? Or maybe the meal planner? Could this be a recipe question? What about the health advisor?” It’s cognitively expensive, token-heavy, and prone to confusion when tool descriptions overlap or seem similar.
This corresponds basically to a unique ReAct reasoner node that has access to all tools and makes use of them as per its criteria.

Intent Classification Approach
Now contrast this with the intent classification approach for the same question:
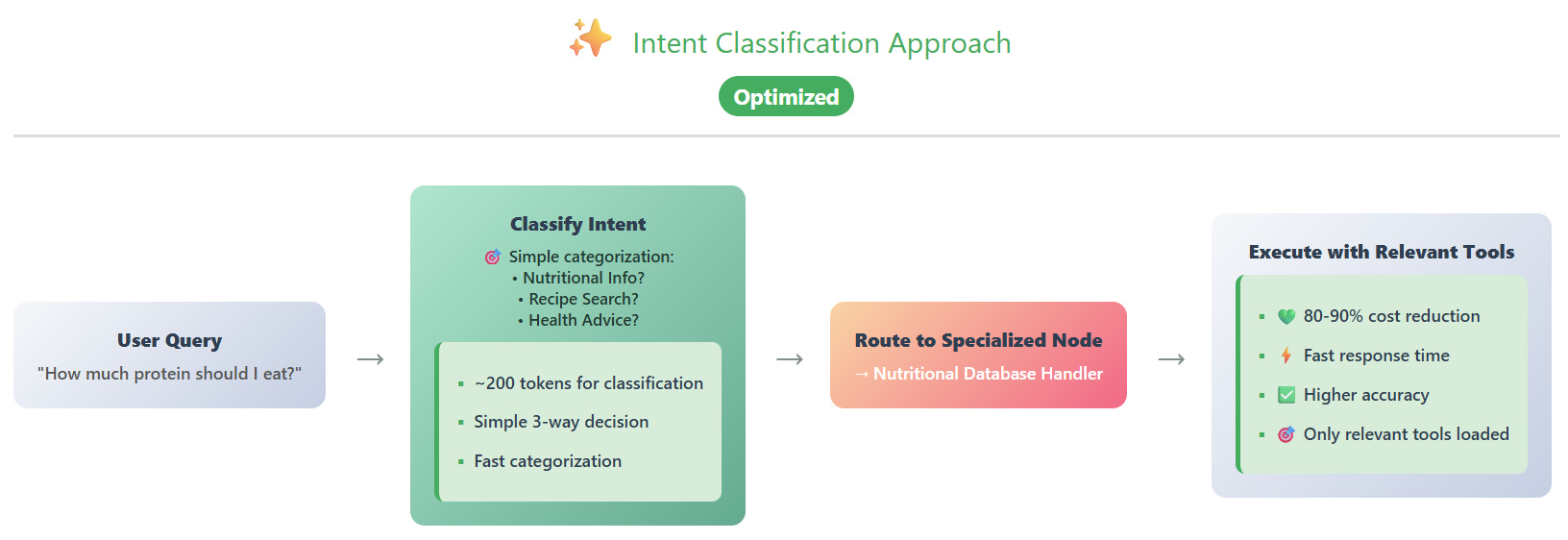
The process is fundamentally different. First, a lightweight classification step asks a single, focused question: “Is this about nutritional information, recipes, or health symptoms?” This simple categorization uses roughly 200 tokens—a fraction of the traditional approach.
Once classified as “nutritional information,” the request routes directly to the specialized nutritional database handler. This handler only needs to know about database queries—it doesn’t load recipe tools, meal planning functions, or any irrelevant capabilities. The decision space is dramatically simplified.
The Impact of This Difference
This architectural shift creates a cascade of benefits. The token reduction (from 2000+ to ~200 for classification, then another ~200-400 for the specialized handler) means you’re using roughly 15-20% of the tokens required by the traditional approach. At scale, this isn’t just a marginal improvement—it’s the difference between a sustainable production system and one that hemorrhages money on API costs.
But beyond cost, there’s a qualitative difference in performance. The traditional approach asks the AI to be a generalist every time, evaluating a complex decision tree for even simple requests. The intent classification approach leverages specialization—the classifier is excellent at categorization, and each handler is excellent at its specific task. It’s the difference between asking one person to be a master chef, nutritionist, and meal planner versus having specialists for each role.
📖 Book of the Week
This week’s pick: “Graph Machine Learning: Learn about the latest advancements in graph data to build robust machine learning models” (Second Edition) by Aldo Marzullo, Enrico Deusebio, and Claudio Stamile.

Who it’s for:
Data scientists, ML engineers, and graph specialists looking to expand their toolkit and work with complex, interconnected data.
What’s inside:
Updated Frameworks: Hands-on examples with PyTorch Geometric and Deep Graph Library (DGL).
New Topics: Explore temporal graph learning and LLM-powered graph ML for modern applications.
Practical Focus: Learn to model relationships, uncover hidden patterns, and solve real-world problems.
Beyond Tutorials: Gain problem-solving frameworks that adapt as tools and libraries evolve.
Why read it:
A comprehensive guide bridging graph theory, machine learning, and AI innovation — ideal for those ready to move from static data to dynamic, graph-driven insights.
🛠️ Do It Yourself
Building an Intent Classification System
Now that we understand the “why,” let’s explore the “how” with a practical example. We’ll build a nutrition AI assistant that can handle three types of requests:
Nutritional information queries (e.g., “How much protein do I need?”)
Recipe searches (e.g., “Find me a low-carb breakfast”)
Health symptom advice (e.g., “I’m feeling tired, what should I eat?”)
It will look like this:
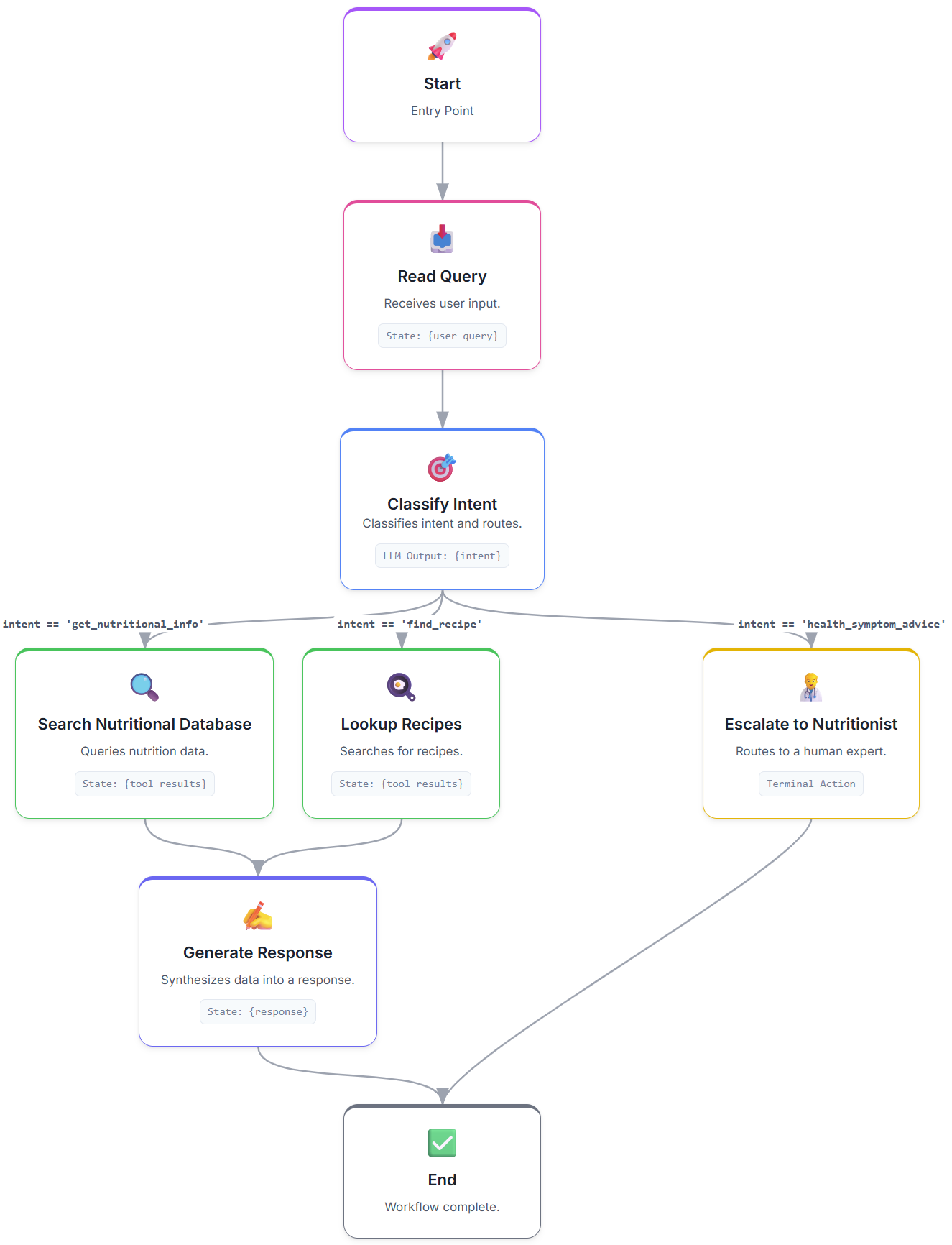
Let’s build it!
Setting Up Our Foundation
First, let’s establish what we’re working with. We’ll use LangGraph, which provides a clean way to build stateful AI workflows, and OpenAI’s GPT-4 for the classification intelligence.
import os
from typing import TypedDict, Literal
from langgraph.graph import StateGraph, START, END
from langgraph.types import Command
from langchain_openai import ChatOpenAI
# Set up your OpenAI API key
os.environ[”OPENAI_API_KEY”] = “your-api-key-here”The libraries here serve specific purposes:
LangGraph gives us a graph-based way to define our workflow
TypedDict ensures our data structures are well-defined and type-safe
Command is LangGraph’s way of both updating state and routing to the next node
Some concepts that you will find useful before diving into the agent’s design:


Let’s begin!
Designing the State: Your Agent’s Memory
Keep reading with a 7-day free trial
Subscribe to Machine Learning Pills to keep reading this post and get 7 days of free access to the full post archives.