

Issue #49 - ARIMA models: Criteria for selection


💊 Pill of the week
Last week we defined the concept of stationarity, introduced some tests to check if our data met those requirements and finally estimated the parameter “d” of our ARIMA model. This week we will see the criteria we will follow to select the rest of the parameters of our model.
👉Also, we will share the answer (notebook) for the last DIY issue at the end of this issue!

But for now, let’s continue with ARIMA:
Defining the criteria
The first step is defining the criteria for the parameters selection, what will we check in the model to say that one model is better than another?
AIC (Akaike Information Criterion) and BIC (Bayesian Information Criterion) are two commonly used model selection criteria in statistical analysis. They assist in comparing and ranking various models based on their fit to the data and complexity.
AIC evaluates the quality of a model by penalizing the number of parameters it employs. The AIC score, computed as the negative log-likelihood of the observed data adjusted by the number of parameters, favours models with lower scores, indicating a better balance between fit and complexity.

BIC operates similarly to AIC but imposes a heavier penalty on the number of parameters in the model. This criterion incorporates both the model's fit to the data and the sample size in its calculation, making it particularly useful when dealing with large datasets to mitigate the risk of overfitting.

When deciding between models, one can use either AIC or BIC to identify the most suitable option. However, it's crucial to acknowledge that the optimal choice depends on the specific problem at hand and the characteristics of the data being analyzed.
You can check a Twitter thread about this here:

Check it in your model
You can find these criteria right after training your ARIMA model, as easy as doing the following:
from statsmodels.tsa.arima.model import ARIMA
model = ARIMA(time_series_data, order=(p, d, q)).fit()
model.summary()The ARIMA.summary() method provides you with a summary of the fitted model. This is an example:
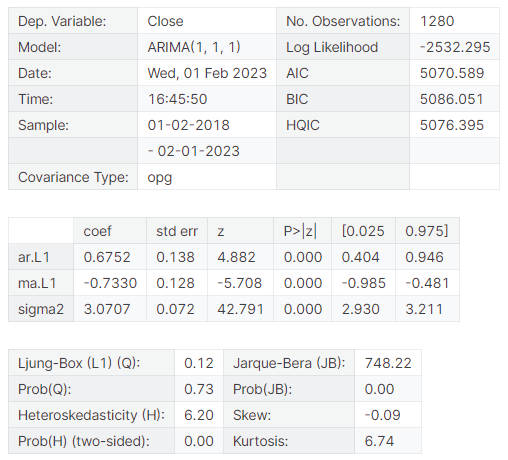
Here's what you should pay attention to in the summary:
Model Summary: This section displays the ARIMA model order parameters (p, d, q), which represent the order of the Autoregressive (AR) part, the degree of differencing (I), and the order of the Moving Average (MA) part, respectively. It also shows the time range of the data used for fitting the model.
Model Statistics: This section provides various statistical measures to evaluate the model's goodness of fit, including:
Log-likelihood: The log-likelihood value of the fitted model.
AIC (Akaike Information Criterion): A measure that combines the goodness of fit and model complexity, used for model selection.
BIC (Bayesian Information Criterion): Another model selection criterion that penalizes complex models more heavily than AIC.
HQIC (Hannan-Quinn Information Criterion): An alternative information criterion that strikes a balance between the AIC and BIC in terms of model complexity penalty.
Coefficients: This part lists the estimated coefficients of the ARIMA model, along with their standard errors, z-statistics, and p-values. The coefficients represent the weights assigned to the AR and MA terms, as well as the constant term (if present). You should check if the coefficients are statistically significant (low p-values) and interpret their magnitudes and signs.
Residual Analysis: This section provides diagnostic information about the residuals (differences between the observed values and the model's predictions). It includes:
Ljung-Box Q-statistic: A test for serial correlation in the residuals. If the p-value is low (typically less than 0.05), it suggests the presence of serial correlation, which violates the ARIMA model assumptions.
Heteroskedasticity tests: These tests check for the presence of heteroskedasticity (non-constant variance) in the residuals. A low p-value (typically less than 0.05) suggests that the residuals have non-constant variance, which can lead to inefficient parameter estimates.
Jarque-Bera statistic: This statistic tests for normality in the residuals. A low p-value (typically less than 0.05) indicates that the residuals are not normally distributed, which violates one of the assumptions of the ARIMA model.
Skewness and Kurtosis: These values provide information about the distribution of the residuals. Ideally, the residuals should have a skewness close to zero and a kurtosis close to 3 (the values for a normal distribution).
By examining these different components of the summary, you can evaluate the ARIMA model's fit, check if the assumptions are satisfied, and determine if any adjustments or alternative models might be necessary.
You can also check my thread about this:

These tools will aid us when selecting the parameters “p” and “q” of our model. We will see that in the next issue!
📧 You can email me with your suggestions here: david@mlpills.dev
🎓Learn Real-World Machine Learning!*
Do you want to learn Real-World Machine Learning?
Data Science doesn’t finish with the model training… There is much more!

Here you will learn how to deploy and maintain your models, so they can be used in a Real-World environment:
Elevate your ML skills with "Real-World ML Tutorial & Community"! 🚀
Business to ML: Turn real business challenges into ML solutions.
Data Mastery: Craft perfect ML-ready data with Python.
Train Like a Pro: Boost your models for peak performance.
Deploy with Confidence: Master MLOps for real-world impact.
🎁 Special Offer: Use "MASSIVE50" for 50% off.
*Sponsored
🤖 Tech Round-Up
No time to check the news this week?
This week's TechRoundUp comes full of AI news. From women all over the world who are shaping the AI future to Particle, the future is zooming towards us! 🚀
Let's dive into the latest Tech highlights you probably shouldn’t this week 💥
1️⃣ 𝗧𝗵𝗲 𝘄𝗼𝗺𝗲𝗻 𝗶𝗻 𝗔𝗜 𝗺𝗮𝗸𝗶𝗻𝗴 𝗮 𝗱𝗶𝗳𝗳𝗲𝗿𝗲𝗻𝗰𝗲 👩🏻💻
From policy advisors to researchers, women are shaping the future of AI, addressing biases, and innovating for a better tomorrow.
2️⃣ 𝗔𝗻𝘁𝗵𝗿𝗼𝗽𝗶𝗰’𝘀 𝗖𝗹𝗮𝘂𝗱𝗲 3 𝗰𝗹𝗮𝗶𝗺𝘀 𝘀𝘂𝗽𝗲𝗿𝗶𝗼𝗿𝗶𝘁𝘆 𝗼𝘃𝗲𝗿 𝗚𝗣𝗧-4 🤖
Anthropic's new AI models are giving GPT-4 a run for its money, boasting improved analysis, forecasting, and multi-modal capabilities.
3️⃣ 𝗘𝗹𝗼𝗻 𝗠𝘂𝘀𝗸 𝘁𝗮𝗸𝗲𝘀 𝗮 𝘀𝘁𝗮𝗻𝗱 𝗮𝗴𝗮𝗶𝗻𝘀𝘁 𝗢𝗽𝗲𝗻𝗔𝗜’𝘀 𝘀𝗵𝗶𝗳𝘁 ⚖️
Elon Musk, Sam Altman, and OpenAI find themselves in court over AI's future direction. The stakes are high as legal battles shape the tech landscape.
4️⃣ 𝗥𝗮𝗯𝗯𝗶𝘁'𝘀 𝗝𝗲𝘀𝘀𝗲 𝗟𝘆𝘂 𝘀𝗵𝗮𝗿𝗲𝘀 𝗮 𝘁𝗮𝗸𝗲 𝗼𝗻 𝘀𝘁𝗮𝗿𝘁𝘂𝗽 𝘀𝘂𝗿𝘃𝗶𝘃𝗮𝗹 🐰
Rabbit's Jesse Lyu shares startup wisdom: Speed is key, but resilience is crucial. It's a rapid race of innovation and adaptation in the startup world.
5️⃣ 𝗣𝗮𝗿𝘁𝗶𝗰𝗹𝗲 𝗿𝗲𝗶𝗺𝗮𝗴𝗶𝗻𝗲𝘀 𝗻𝗲𝘄𝘀 𝗰𝗼𝗻𝘀𝘂𝗺𝗽𝘁𝗶𝗼𝗻 𝘄𝗶𝘁𝗵 𝗔𝗜 📰
Former Twitter engineers unveil Particle, an AI-powered news reader. It promises a personalized news experience, revolutionizing how we stay informed.
📝Check if you were right!
Here you have a notebook with the answer to the previous DIY issue about Feature Importance. Apologies for the delay, this should have been sent last week!
Here you have it:
Keep reading with a 7-day free trial
Subscribe to Machine Learning Pills to keep reading this post and get 7 days of free access to the full post archives.